
CUDA core 같은 경우에는 범용적인 SIMD 연산기 이다. ( 지금까지 해당 파트를 배운 것이고. )
반면에 , Tensor Core 는 딱 하나의 연산만 한다. 이 연산이 어떻게 보면 AI 에서 아주 유용하게 nvidia gpu 를 사용할 수 있게 한 꽃이라고 할 수 있다.
MMA ( mixed-precision matrix multipy )
** D = A*B + C 8*
해당 연산이 Tensor core 에서 수행되는 연산이다. 이 연산이 딥러닝에서 90%이상 차지한다고 보면된다.
(Attention QK , Linear layer , conv , 등... )
volta ( v100 ) 에서 처음 도입되고 , 지금은 blackwell 까지 와서 SM 당 4개씩 존재한다고 한다.


연산은 너무 간단해서 깊게 설명할 것 까지는 없으나 , 몇가지 특징이 존재한다.
(1) Mixed precision
A,B 는 FP16 으로 읽고, 곱셈은 FP16
accumluation ( +C) 는 FP32 로 합니다.
곱셈은 값의 크기를 크게 바꾸지 않지만, accumulation 은 엄청 많은 항을 더하면서 오차가 쌓이기 때문에 더 높은 정밀도가 필요하다고 한다. 그래서 그냥 +c 부분도 FP16 만으로 누적하면 결과가 망가진다.
입력은 가볍게 하고 , 누적을 안전하게 하는 방식으로 보면된다.
(2) Warp-level operation
CUDA core는 thread-levl (각 thread 가 자기연산)만 한다.
Tensor core 에서는 32개 thread (warp)가 협력해서 하나의 행렬 연산(matrix fragment)을 처리한다.
( 그래서 Tensor Core programming에서는 일반 CUDA처럼 “thread 하나가 output element 하나 계산”하는 방식보다, warp 단위로 matrix tile을 처리한다고 이해해야 한다. )
중요한 내용이라 이해를 위해 예시 (with claude)
시나리오: 16×16 행렬 곱 C = A·B 한 번 계산
방식 1: 기존 CUDA Core 방식
각 thread가 C의 원소 하나를 담당합니다.
thread (0,0) → C[0][0] 계산 → for k: A[0][k] * B[k][0] 누적
thread (0,1) → C[0][1] 계산 → for k: A[0][k] * B[k][1] 누적
thread (5,7) → C[5][7] 계산 → for k: A[5][k] * B[k][7] 누적
...
thread (15,15) → C[15][15] 계산총 256개 thread가 각자 독립적으로 자기 원소를 계산해요. 서로 대화 안 합니다. 각 thread 입장에서는 "나는 내 한 칸만 책임진다".
방식 2: Tensor Core 방식
32개 thread (1 warp)가 통째로 16×16×16 행렬 곱 하나를 처리합니다.
warp의 32개 thread가 모두 모여서:
├─ thread 0: A의 어떤 조각 + B의 어떤 조각 + C의 어떤 조각을 register에 들고 있음
├─ thread 1: A의 다른 조각 + B의 다른 조각 + C의 다른 조각을 register에 들고 있음
├─ ...
└─ thread 31: A의 또 다른 조각 + ...
→ wmma::mma_sync() 호출
→ Tensor Core가 32 thread의 register를 한꺼번에 읽어서
하드웨어 회로로 행렬곱 처리
→ 결과 D의 조각들을 다시 32 thread의 register에 분배여기서 thread 하나만 보면 자기가 뭘 계산하는지 모릅니다. "C[5][7]은 내가 책임진다" 같은 1대1 매핑이 없어요. 그냥 "나는 fragment의 일부 데이터를 들고 있고, 32명이 같이 mma_sync를 부르면 어떤 마법이 일어나서 결과가 나온다"인 거예요.
진짜 차이는 뭐냐
(1) 누가 일을 하느냐
| 일하는 단위 | thread 1개 | warp 32개 thread |
| 한 번에 처리하는 출력 | scalar 1개 | 행렬 조각 (예: 16×16) |
| 코드 작성 시점 | thread 관점 | warp 관점 |
(2) 코드 작성 mental model이 완전히 다름
CUDA Core 코드 짤 때:
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
float sum = 0;
for (int k = 0; k < K; k++) {
sum += A[row][k] * B[k][col]; // 내 행, 내 열, 내 누적
}
C[row][col] = sum; // 내 칸에 저장"나(thread)"가 주어. 내가 어떤 row, 어떤 col을 맡았는지 명확.
Tensor Core 코드 짤 떄
wmma::fragment<matrix_a, 16,16,16, half, row_major> a_frag;
wmma::fragment<matrix_b, 16,16,16, half, row_major> b_frag;
wmma::fragment<accumulator, 16,16,16, float> c_frag;
wmma::fill_fragment(c_frag, 0.0f);
wmma::load_matrix_sync(a_frag, A_ptr, 16); // 32 thread가 같이 부름
wmma::load_matrix_sync(b_frag, B_ptr, 16); // 32 thread가 같이 부름
wmma::mma_sync(c_frag, a_frag, b_frag, c_frag); // 32 thread가 같이 부름
wmma::store_matrix_sync(C_ptr, c_frag, 16, mem_row_major);"나(thread)"가 안 보여요. 주어가 "우리 warp"예요. 각 함수는 32 thread가 동시에 같은 값으로 호출해야 합니다. 한 명이라도 다른 인자로 부르면 undefined behavior.
(3) "fragment"가 그 추상화의 핵심
a_frag는 표면적으로는 한 변수처럼 보이지만, 실제로는 32개 thread의 register에 분산 저장된 행렬 조각이에요. 즉:
- thread 0의 a_frag ≠ thread 5의 a_frag — 각자 다른 데이터 일부를 들고 있음
- 그런데 코드상에서는 그냥 a_frag라는 하나의 변수로 보임
- 누가 어떤 원소를 들고 있는지는 하드웨어가 알아서 정함 (opaque layout — 프로그래머가 신경 쓸 필요 없음)
이게 처음에 굉장히 어색합니다. 일반 변수처럼 생겼는데 사실 32명이 나눠 들고 있는 공유 객체. "나는 a_frag[0][0]을 들고 있나?" 물어봐도 의미 없어요. 그건 알 필요가 없게 설계돼 있어요.
그래서 실용적으로 뭐가 바뀌나
p.23 예제 (matmulT) 다시 봐보세요:
int warp = (blockDim.x * blockIdx.x + threadIdx.x) / warpSize;
int cx = warp % (Bx/16);
int cy = warp / (Bx/16);여기서 warp 변수가 핵심이에요. thread index를 32로 나눠서 이 thread가 속한 warp의 ID를 구합니다. 그리고 그 warp ID로 "이 warp가 C의 어느 16×16 타일을 책임지는가"를 정해요.
즉, 일반 CUDA에서 "이 thread가 C의 어느 원소를 책임지는가"를 정했다면, Tensor Core에서는 "이 warp가 C의 어느 타일을 책임지는가"로 한 단계 올라간 거예요. tile은 16×16이니까 한 warp가 256개 원소를 한 번에 처리하는 셈이고, 그게 mma_sync 한 번으로 끝납니다.
한 줄 요약
CUDA Core는 "1 thread = 1 output element", Tensor Core는 "1 warp = 1 output tile". 코드의 주어가 thread에서 warp로 올라가고, 그 warp 안의 32 thread는 fragment를 나눠 들고 협력 호출을 한다.
이 mental model 전환이 익숙해지면 그 다음 페이지들(WMMA API, shared memory 버전 등)이 훨씬 잘 읽힙니다. 더 헷갈리는 부분 있으면 알려주세요.

FMA = Fsed Multipy-add
즉 , a*b+c 를 한번의 연산으로 처리하는 것이다.
여기서 유의할 점은
- 곱셈 한번(a*b) + 덧셈 한번 = floating-point 연산 (FLOP) 2개
- 하드웨어 입장에서는 회로 하나로 한사이클 처리 = FMA 1개
이걸 딱 잡고 왼쪽 아래 그림을 살펴보면,
(우리는 C = A*B+C , 즉 다시말해 C+=A*B 의 형태를 보기로 약속한다. )
1. 입력 (A,B) - FP 16 으로 저장
2. 곱셈 : FP16 x FP16 , 결과는 full precision 으로 받는다 ( 오버플로 이런거 방지 )
3. 누적 : 결과를 FP32 에 누적한다 ( 이렇게하면 오차가 상대적으로 적어지고 )
4. 출력 : FP32
(volta 기준)
이번에는 오른쪽 아래 그림을 살펴보자 : 4x4x4 MMA
D(4×4) = A(4×4) × B(4×4) + C(4×4)
volta 에서 tensor core 1개가 한클럭에 처리하는 최소 단위이다. 4x4 행렬 3개를 받아서 (a,b,c) -> 4x4 행렬을 하나 뱉는다.
FMA 개수
- 출력 D (4x4) = 16개
- D[I][J] 가 A 의 row 한줄, B 의 col 한줄 + C 하나 이므로 , 총 4번의 FMA 를 해야한다. (4X4 니까그냥..)
- 총 FMA = 16개 원소 * 4 ( 바로 위에서 구한게 4번의 FMA ) = 64 FMA
즉, 64 FP16/FP32 FMA operations per clock per Tensor Core
(FLOPS 로 계산하면 64*2 = 128 FLOPS. )
SM 단위로 살펴보자.
Volta 에서 하나의 SM 에는 tensor core 가 8개 존재한다.
따라서..
TC 1개당 64 fma/clock
*8개 (SM당 )
--> 512 FMA / CLOCK / SM
(FLOPS = 1024 )
이다.

WMMA = warp matrix mltiply-accumulate
이름 그대로 warp 가 협력해서 하는 MMA 를 호출하는 cuda c++ api 이다.
(위에서 설명했듯이 , Tensor core 는 thread 하나가 혼자하는 연산이 아니라 , warp 단위로 협력해서 수행하는ㅇ ㅕㄴ산. )
코드를 하나씩 살펴보자.
#include <mma.h>
using namespace nvcuda;
__global__ void wmma_ker(half *a, half *b, float *c) {
__global__ 이므로 GPU 에서 도는 커널이다. 입력 A,B 는 fp16 포인터 , 출력 c 는 fp32 포인터이다. ( mixed precision )
fragment 선언
wmma::fragment<wmma::matrix_a, 16, 16, 16, half, wmma::col_major> a_frag;
wmma::fragment<wmma::matrix_b, 16, 16, 16, half, wmma::row_major> b_frag;
wmma::fragment<wmma::accumulator, 16, 16, 16, float> c_frag;fragment는 "warp 32개 thread가 나눠 들고 있는 행렬 조각"을 담는 컨테이너이다.
( 행렬 전체가 아니라 , Tensor core 연산에 필요한 작은 행렬 조각 )
일반 변수처럼 보이지만 실제로는 32 thread의 register에 흩어져 저장되고, 어떤 스레드가 뭘 가지고 있는지는 알 수 없다 ( 컴파일이 알아서 정함 ! )
인자 정리
matrix_a : fragment 의 역할
M,N,K ( 2,3,4 번째 인자) : 16 ,16 ,16
half : element type ( fp16 )
col_major : layout
다시 좀 풀어서 설명을 해보자면,
a_frag는 변수 하나처럼 생겼지만, 실제로는 warp 안의 32개 thread가 16×16 행렬을 256조각으로 나눠서 각자 register에 들고 있는 상태이다.
( 그러면 한 thread 당 = 256 / 32 = 8개 원소를 가지고 있게 되겠다 - 다만 , 각 thread 별로 접근은 불가능 ! )
M,N,K 란?
A: M × K (M행, K열)
B: K × N (K행, N열)
로 정의된다
다만 이 숫자는 이후에 말하는 표에서만 골라서 연산할 수가 있다.
col_major / row_major
: c++ 배열이 기본적으로 row_major 이기는 하나 , col_major 인 경우도 있다. 따라서 tensor 에 넘겨줄때 해당 행렬이 어떤 방식으로 저장되어 있는지 알려주어야 한다.
**특이점*
wmma::fragment<wmma::accumulator, 16, 16, 16, float> c_frag;
C/D(accumulator) 에는 lay_out 이 없다.
C/D 의 layout 은 선언 시점이 아니라 , load&stor 시점에 정해진다고 한다.
누적 변수 0으로 초기화
wmma::fill_fragment(c_frag, 0.0f);c += a*b 를 하기 이전에 c 를 먼저 0으로 설정하는 모습.
여기서도 유의해야할 점은 32thread 가 모두 같이 호출된다는 점 !
메모리에서 fragment로 데이터 로드
wmma::load_matrix_sync(a_frag, a, 16);
wmma::load_matrix_sync(b_frag, b, 16);앞에서 a_frag 를 선언하기는 했지만 , 아직 데이터는 없는 상태이다.
원본 데이터는 global memoryt a 배열에 저장되어 있는데 , 이걸 fragement 로 옮기는 것이 load_matrix_sync 함수이다.
global memory a 배열에서는 256 개 원소가 쭉 있을 것이고 이걸 loabl_matrix_sync 로 가지고 오면
-> warp 32 thread register 에 각 thread 마다 8개씩 넣는다 ! ( = a_frag )
인자에서 가장 헷갈리는 부분이 마지막에 있는 "16" 부분이다.
이게 leading dimension (= stride ) 를 말하는 부분이다.
(메모리는 1차원인데 , 행렬은 2차원 이므로 . 어디서 한행이 끝나고 다음행 시작인지를 알려주기 위함 )
지금 우리 예시에서는 16x16 을 가정하고 있지만 , 1024x1024 같이 큰 행렬이 있다면 이를 16x16 타일로 쪼개서 처리해야한다.
이떄는 stride 가 1024 가 되고 ( 다음 행으로 옮기는데 1024 개를 건너 띄워야 하니까.. ) 이 경우에는 stride=1024 값을 주면되는 식이다.
// 조각만 따로 저장된 경우
wmma::load_matrix_sync(a_frag, a, 16); // stride = 조각 너비
// 큰 행렬(너비 1024)의 일부를 읽는 경우
wmma::load_matrix_sync(a_frag, &A[tile_pos], 1024); // stride = 원본 너비
cf.
함수뒤에 익숙한 _sync 가 존재하는데 여기서는 warp 의 32thread 가 모두 여기 올 때 까지 기다린 다는 의미이다
( 어찌보면 당연하다. 여기서는 warp 단위로 실행한다고 했으니. )
fragment 는 32 thread 가 다 같이 모여서 256 개 원소를 협력해서 읽어야 한다 ( 누구라도 빠지면 데이터가 불완전 ) !
(일반적인 CUDA 에서 thread 별로 데이터를 관리하는 것과 아예 다르다 ! )
wmma::load_matrix_sync(a_frag, a, 16);
에서 32thread 가 동시에 부르면..
- 32 thread가 barrier에서 모임 (_sync)
- 하드웨어가 256개 원소(16×16)를 32 thread에게 분배 (한 명당 평균 8개)
- 각 thread가 자기 몫을 global memory에서 읽어 자기 register에 적재
- 이제 a_frag가 데이터로 채워짐 → mma_sync 호출 준비 완료
이런 루트로 내부에서 일어난다고 보면 된다.



( 전반적인 설명은 필기본으로 대체 )

< NVFP4 ( 4비트 추론 ) >

NVFP4 는 숫자 하나를 4비트로 표현한다 ( 표현가능한 값 16 개 )
NVFP4 (E2M1): [S][E×2][M×1] = 4 bits
표현범위는 대략 -6~6
실제 값: 0, 0.5, 1, 1.5, 2, 3, 4, 6 (그리고 음수 버전)
값을 8개 밖에 사용하지 못하는데 어떻게 이걸 추론에 사용할까 ?
(weight 같은 경우는 실수값으로 매우 다양한데 , 이를 뭉개버리면 정보 손실이 크다. )
NVFP4는 크게 두가지 해결책을 사용해서 이를 해결한다 .
(1) high-precision scale encoding
"값 자체" <=> "배율(sclae) " 을 따로 저장한다
실제 값 == (4bit index) * (배율 scale)
(2) two-level micro-block scaling
해당 배율을 어떻게 저장할지에 대한 방법이다.
1. 16개씩 묶어서 micro-block마다 배율 (E4M3 FP8)
텐서 전체를 16개 값씩 잘게 쪼갠다. 이 16개 묶음을 micro-block이라 하고, 각 묶음마다 하나의 배율을 공유한다.
그래서 각 블록마다 FP8 배율 1개를 공유하는 형식이다.
2. 텐서 전체에 배율을 하나더 (FP32 )
그리고 그 위에 텐서 전체에 적용되는 글로벌 배율을 FP32 로 하나 더 얹는다.
복원값 = 4비트 index * 블록 FP8 배율 * 텐서 32배율
이 두가지 배율 덕분에 4비트라는 엄청난 압축에도 정확도를 비슷하게 가져갈 수 있다.
NVFP4 = 4비트 거친 값(E2M1) + 16개 블록마다 FP8 배율 + 텐서당 FP32 배율.
이를 주로 추론 가속용에 사용한다
최근들어 LLM 같은 경우에 inference 의 비용을 줄이는게 더 중요하다 ( 학습은 한번 비싼 값으로 하는건 ok , 하지만 사용자들이 사용하는 추론 비용은 줄여야한다 ) 라는게 트랜드이고 정설인 것으로 아는데 , 엔비디아가 이에 맞추서 이런 하드웨어를 미리 만들어둔게 아닐까 싶다
(허용되는 조합 - 참고용 )
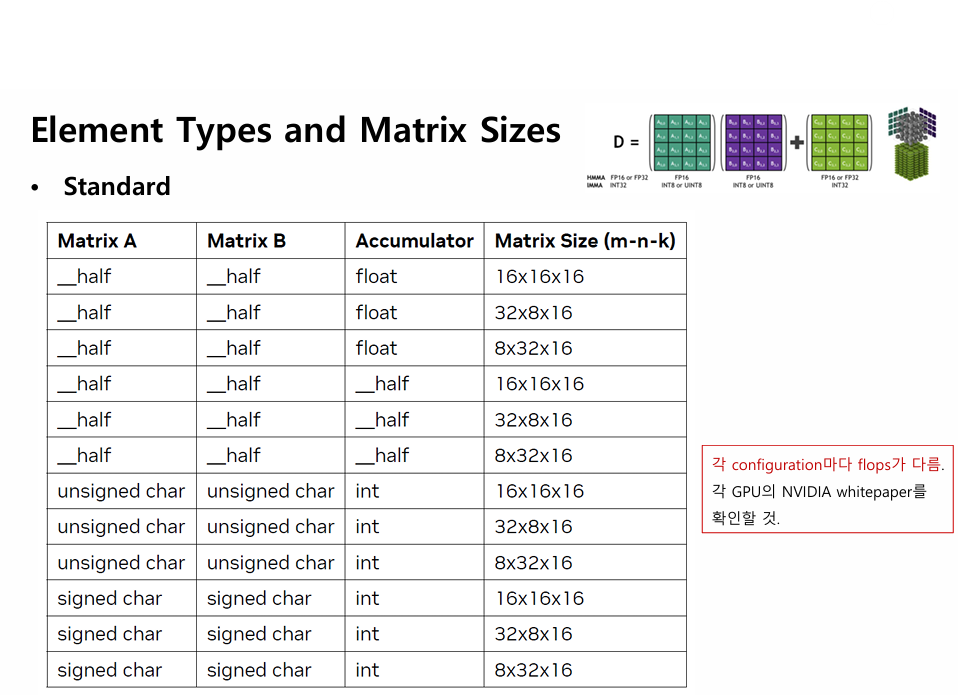

Matrix Multiplication Using Tensor Cores
이제 배운 것들의 총 정리본이 되겠다.
이파트는 (아마도) 시험에 가장 잘 나오기도 쉽고 무엇보다 차원계산을 좀 머리속에 담아둔 채로, 특히나 지금까지는 thread level 의 컨셉을 가지고 했다면 , 여기서는 warp 단위로 생각해야하는게 가장 좀 까다롭다.
하지만 한번 하고나면 또 근본적으로 많이 다를게 없기 때문에 괜찮다.
한편 살펴보도록 하겠다 !.
Matrix Multiplication without Using Shared Memory
__global__ void matmulT(float* __restrict C, const half* __restrict A, const half* __restrict B,
int Ay, int Ax, int Bx) {
int warp = (blockDim.x * blockIdx.x + threadIdx.x) / warpSize; // grid 내 warp 번호
int cx = warp % (Bx / 16); // 이 warp가 맡은 C 타일의 (x=열,
int cy = warp / (Bx / 16); // y=행) 좌표
int Atile_pos = cy * 16 * Ax; // A 첫 타일 시작 위치 (행 방향)
int Btile_pos = cx * 16; // B 첫 타일 시작 위치 (열 방향)
// fragment 선언 (전부 16x16x16)
wmma::fragment<wmma::matrix_a, 16,16,16, half, wmma::row_major> a_frag;
wmma::fragment<wmma::matrix_b, 16,16,16, half, wmma::row_major> b_frag;
wmma::fragment<wmma::accumulator, 16,16,16, float> c_frag;
wmma::fill_fragment(c_frag, 0.0f); // C 타일을 0으로 초기화
for (int k = 0; k < Ax / 16; k++) { // 타일 단위 누적 루프
wmma::load_matrix_sync(a_frag, &A[Atile_pos], Ax); // A 타일 로드
wmma::load_matrix_sync(b_frag, &B[Btile_pos], Bx); // B 타일 로드
wmma::mma_sync(c_frag, a_frag, b_frag, c_frag); // C += A*B
Atile_pos += 16; // A에서 오른쪽으로 한 타일 이동
Btile_pos += 16 * Bx; // B에서 아래로 한 타일 이동
}
wmma::store_matrix_sync(&C[(cy * Bx + cx) * 16], c_frag, Bx, wmma::mem_row_major);
}
'GPGPU' 카테고리의 다른 글
| GPGPU 총정리 (shared memory , global memory , texture memory) - (5) (0) | 2026.05.16 |
|---|---|
| GPGPU 총정리 ( 중간고사 총정리 )- (4) (1) | 2026.05.16 |
| GPGPU 총정리 - (3) (0) | 2026.03.25 |
| GPGPU 총정리 - (2) (0) | 2026.03.21 |
| GPGPU 총정리 - (1) (0) | 2026.03.05 |