GPGPU 총정리 - (2)
What is CUDA ?

CUDA 란 무엇인가 ?
NVIDIA GPU의 병렬 연산 엔진을 활용하기 위한 범용 병렬 컴퓨팅 플랫폼이자 프로그래밍 모델이다.
사실 와닿지 않으니가 직관적으로 정리해보면
- GPU 하드웨어 : 진짜 계산하는 기계
- CUDA : 그 기계를 프로그래머가 쓰게 해주는 규칙 ( api , 컴파일 방식, 모델 등등 )
간단하게 cuda 를 계산 장치로 다루는 방식 정도로 이해하면 될 것 같다.
CUDA 가 왜필요한가 ?
GPU 는 많은 수의 연산 유닛으로 같은 종류의 계싼을 엄청 동시에 많이 처리하는데 강하다.
CUDA 는 이런 상황에서 " 이 많은 데이터 각각에 대해 같은 연산을 해라 " 를 gpu 에게 효율적으로 시키는 방식(모델) 이다.
기본적으로 CUDA 는 큰 문제 를 아주 작은 작업(task)로 쪼개고 그걸 수많은 thread 로 병렬 처리한다.
Driver API vs Runtime API
엄청 중요한건 아니고 Driver API 는 더 low-levl 이고
Runtime API 는 상대적으로 high levl 이다. 보통 cuda 프로그래밍할때 runtime api 를 쓰는걸로 알고 있다.

Compute Cability (CC) 란?
GPU의 세대/기능 수준 표시정도로 알면된다.
다만 설명자체를 딱히 할 부분은 없어서 넘어가겠다.
< 용어정리 >

1. Kernel
GPU 에서 실행되는 "함수" 이다.
CUDA 에서는 특별한 함수 하나를 GPU 에 올려서 , 그 함수를 엄청 많은 thread 가 동시에 실행하게 한다.
거기서 "함수" 가 kernel 이다.
예시로
__global__ void add(float* A, float* B, float* C) {
int i = ...
C[i] = A[i] + B[i];
}
여기서 add 함수 가 kernel 이다.
그래서 커널 하나를 실행한다는건 이 연산을 GPU 의 많은 thread 에게 동시에 시키는거라고 보면 된다.

위 그림을 보면서 이해하면 빠를 것 같다.
2. Thread
thread는 커널의 한 실행 인스턴스, 혹은 작업 한 개를 맡는 추상적 실행 단위다.
task 를 thread 라고 하고 , 실제로 cuda 에서 각각의 data element 에 대입이 되는 느낌이다.
( 다만 모든 문제에서 무조건 data element 당 1:1 인 것은 아니고 .. )
정확히 말하면:
- CUDA thread = 프로그래머가 쓰는 논리적 실행 단위
- CUDA core / SM / warp scheduler = GPU 안의 물리적 실행 자원
즉, thread는 “일감 하나”를 표현하는 단위에 가깝다.
1. 비유로 먼저 잡자
예를 들어 공장에 기계 10대가 있는데, 처리해야 할 박스는 10,000개라고 하자.
이때:
- 박스 10,000개 = CUDA threads
- 실제 기계 10대 = 물리적인 연산 자원(CUDA cores 등)
박스가 기계보다 훨씬 많아도 괜찮다.
기계가 박스를 한 번에 조금씩 처리하고, 다음 박스를 또 처리하면 된다.
CUDA도 비슷하다.
- thread를 수천, 수만, 수백만 개 만들어도
- 실제 GPU가 그걸 한 번에 전부 물리적으로 동시에 돌리는 건 아니다
- 가능한 만큼만 동시에 실행하고
- 나머지는 순서대로 이어서 처리한다
2. 그럼 thread는 “가짜”냐?
가짜라고 하면 좀 이상하고,
“논리적이다” 라고 하는 게 맞다.
즉 thread는 실제로 의미가 있다.
각 thread는 자기만의:
- thread index
- register state
- program counter 같은 실행 문맥
- local 변수
를 가진다.
하지만 그 thread 하나하나가 독립된 물리 코어 하나에 대응되는 건 아니다.
3. 왜 “추상적 실행 단위”라고 부르냐?
네가 CUDA 코드를 짤 때는 보통 이렇게 생각하잖아:
int i = blockIdx.x * blockDim.x + threadIdx.x;
C[i] = A[i] + B[i];
여기서 threadIdx.x가 다르면 각 thread가 다른 원소를 처리한다.
즉 프로그래머 입장에서는:
- 0번 thread
- 1번 thread
- 2번 thread
- ...
- 999999번 thread
이 각각 존재한다고 생각하고 코드를 짠다.
이건 프로그래밍 모델이다.
그런데 하드웨어 입장에서는 이 많은 thread를 실제로는:
- warp(32개) 단위로 묶고
- SM 위에서
- 스케줄러가 가능한 warp를 골라
- 순차/병렬 섞어서 실행한다
즉 프로그래머가 보는 thread 세계와
하드웨어가 실제 처리하는 방식이 다르다.
4. CPU thread랑도 조금 다르다
CPU에서 thread라고 하면 보통:
- OS가 관리하고
- 스택도 있고
- context switch 비용도 있고
- 꽤 무거운 실행 단위
이런 느낌이 있다.
CUDA thread는 훨씬 가볍고, 훨씬 많이 만들 수 있고, GPU용으로 설계된 thread다.
그래서 CUDA thread를 보고
“이게 OS thread 같은 건가?”
라고 생각하면 안 된다.
5. 그러면 실제 물리적 실체는 뭐냐?
CUDA에서 실제 물리적 실체에 더 가까운 건 이런 것들이다.
- SM: block/warp를 실행하는 큰 하드웨어 단위
- warp scheduler: ready된 warp를 고르는 스케줄러
- CUDA core: 산술 연산 수행 유닛
- register file / shared memory: thread들이 쓰는 실제 저장 자원
즉 thread 자체가 금속으로 된 어떤 부품인 건 아니고,
그 thread를 실행시키기 위한 상태와 연산 자원은 실제 하드웨어에 존재한다고 보면 된다.
6. 아주 중요: thread와 core는 1:1이 아니다
이게 핵심이다.
많이들 처음에 이렇게 생각한다:
thread 1024개 만들었으면 core도 1024개 필요하나?
아니다.
예를 들어:
- thread 1024개 생성
- block 256개씩 4 block
- 각 block은 8 warps
- GPU는 available한 SM들에서 이 warp들을 차례로 실행
즉 thread가 많다는 건
할 일이 많다는 뜻이지,
그 개수만큼 물리 코어가 생긴다는 뜻이 아니다.
7. 그럼 thread는 어디에 “존재”하냐?
좋은 질문이다.
정확히는 thread는 **실행 상태(context)**의 형태로 존재한다고 보면 된다.
각 thread는 실행 중에 필요한 상태를 가진다:
- 지금 몇 번째 instruction까지 왔는지
- 어떤 register 값을 갖고 있는지
- 자기 thread index가 뭔지
이런 상태는 GPU 내부 자원에 유지된다.
그래서 완전히 허상은 아니다.
다만 “하드웨어 부품 하나”로 존재하는 건 아니다.
8. 한 줄로 정리
네 질문에 가장 직접적으로 답하면:
CUDA thread는 물리 코어 같은 실체가 아니라, GPU 위에서 실행될 작업을 표현하는 논리적 실행 단위다.
다만 실행될 때 필요한 상태(register, PC 등)는 실제 하드웨어 자원에 저장된다.
9. 더 직관적으로 구분
이렇게 구분하면 된다.
[논리적 개념]
thread -> block -> grid
[물리적 하드웨어]
warp scheduler -> SM -> CUDA cores / registers / shared memory
즉
- 너는 thread/block/grid로 코드를 짠다
- GPU는 그걸 warp/SM 중심으로 실제 실행한다
10. 네가 지금 딱 이해해야 할 포인트
지금 단계에서는 이것만 정확히 잡으면 된다.
A. thread는 “일 하나”
예: 벡터 덧셈에서 원소 하나 담당
B. thread는 물리 코어가 아님
실제 하드웨어 자원 위에 스케줄링됨
C. 실제 하드웨어는 warp 단위로 움직임
thread 32개가 warp로 묶여 처리됨
D. 그래서 CUDA는 엄청 많은 thread를 만들어도 됨
GPU가 알아서 나눠서 처리함
원하면 내가 다음 답변에서
“logical thread ↔ physical warp/SM 관계”를 ASCII 그림으로 아주 직관적으로 다시 보여주겠다.
3. Thread Block
block 은 thread 를 여러 묶음으로 묶은 그룹이다 ( 말이 이상하네 )
이때 보통 독립적으로 병렬 처리된다.
그래서 이 block 단위로 GPU 가 배치하고 관리한다.
block 안의 thread 들은 같은 블럭에 속해 있을 뿐만 아니라
- shared memory 공유할 수 있고 ( 중요 )
- 동기화도 가능하다 ( 물론 이것도 block 내부에서만 ! )
다만 , 다른 block 끼리는 독립적으로 움직인다. ( 예외도 있지만 그건 나중에 )
4. Grid
grid 는 전체 block 의 집합이다.
그래서 kernel 한번으로 생성되는 block 의 모음으로 보면 되겠다.
( grid = 이번 kernel(함수) 실행 전체 규모 )
5. warp
저번에도 다뤘지만 중요한 개념이다.
- warp 는 trehad block 이 다시 쪼개진 더 작은 처리 단위이다.
- CUDA 에서는 32 thread로 구성되고 , GPU 의 기본 processing unit 이다.
그래서 예를들어서 block이 256 thread 라면
256 / 32 = 8개의 warp 생김.
GPU 는 warp 단위로 스케줄링하고 실행한다.
가장 중요한건 thread block 을 어떻게 넣느냐 보다 warp 를 지금 내가 어떻게 다루고 있는지가 개발자가 가장 신경써야 하는 부분이라고 한다.
[ 이 5개는 자주 헷갈리기도 하고 , 여기서 용어 관계를 정리를 잘 해야 하므로 외워두고 가도록 하자. ]
(* 예시 ) 벡터 덧셈
C[i] = A[i] + B[i]를 N개 원소에 대해 한다고 하자.
CUDA 식으로 생각하면:
- kernel: “원소 하나 더하라”는 GPU 함수
- thread: 각 원소 i 하나 담당
- block: thread 256개 같은 묶음
- grid: 전체 N개 원소를 덮도록 필요한 block 전체
- warp: block 안에서 32개 thread씩 하드웨어가 처리
예를 들어 N=1024, block=256이면
- 총 thread = 1024
- block 수 = 4
- 각 block 안 warps = 256 / 32 = 8
가볍게 보고 넘어가자.
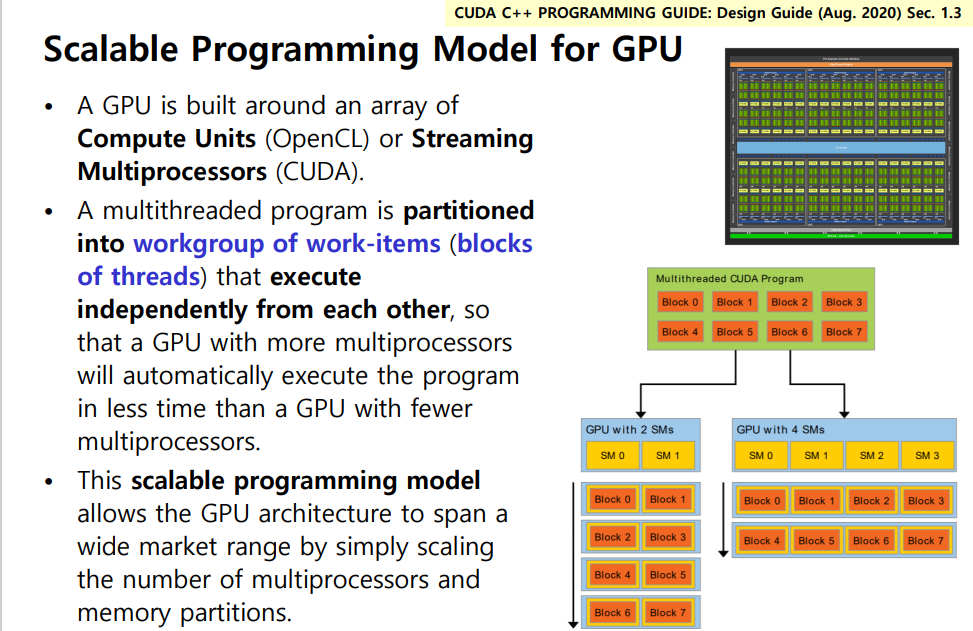
GPU를 Streaming Multiprocessor(SM) 들의 배열로 보고, multithreaded program을 독립적으로 실행 가능한 block들로 나눔으로써, SM이 많은 GPU에서는 더 빨리 실행되도록 설계된 모델이라고 설명한다. 이걸 scalable programming model이라고 부른다.
이렇게 구성이 되면 오른쪽 그림처럼 SM 의 수가 달라져도 프로그램이 GPU 크기에 맞춰 자동으로 스케일 된다고 한다.
( 교수님 피셜로는 사실 이건 이상적인거고 엔비디아에서 아마 GPU 마다 적당한 최적화는 따로 한다고 하신다. )
어쨌든 이게 가능하려면 핵심 전제는
"block 끼리 독립적이여야 한다"
그래야 어떤 block 을 먼저 실행하든 탈이 나지 않는다.
그래서 block 은 독립적으로 실행된다는 사실을 한번더 짚고 넘어가는게 좋겠다.
CUDA Execution Model
이번 챕터의 꽃이라고도 할 수 있겠다. 강의에 여러가지 중요한 포인트가 있는데 , 이걸 이해해야 그 뒤도 이해할 수 있기 때문에 아주아주 자세히 파보려고 한다.
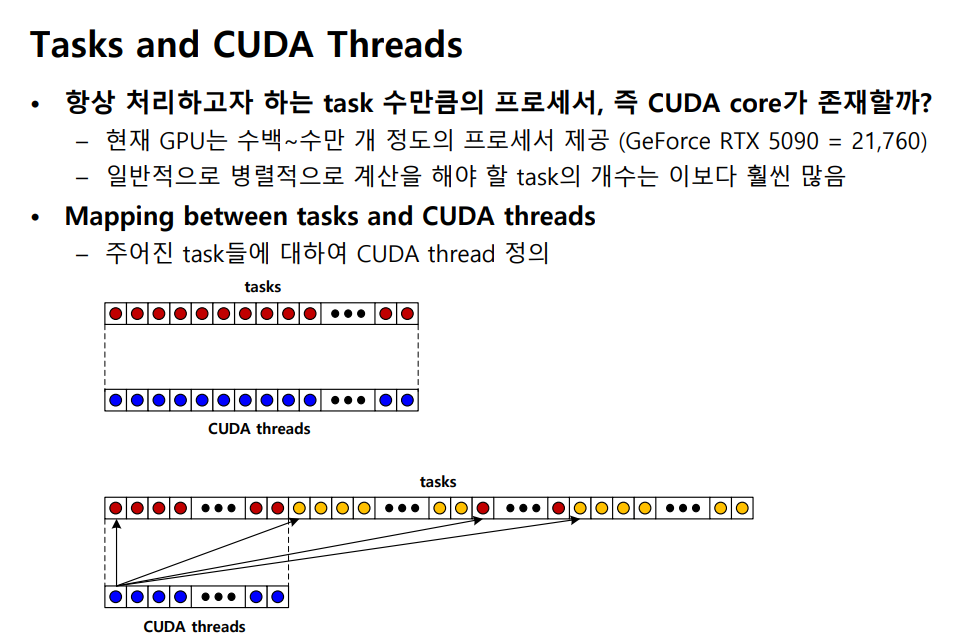
강의 자료 설명 그대로 보통 task 가 CUDA core 보다 훨씬 많다.
그니까 task 1 개 = CUDA core 1개에 바로 올라가는 이런 이상적인 상황 ( 그림에서 위쪽 상황 ) 은 발생하지 않는다고 보면 된다.
따라서 처리해야할 일이 많은데 , 코어는 제한되어 있으니
-> 각 tasks 들을 논리적 thread 로 표현해두고 -> GPU 가 이를 겹쳐서 처리하도록 하자.
그래서 문제의 각 작업 단위를 CUDA thread 라는 추상적인 실행 단위로 표현 한다.
( thread 는 물리 코어가 아니라 논리 작업 단위임 )

이제는 잘 알고 있지만 , thread 를 그냥 하나씩 두는게 아니라 block 으로 묶는다.
전체 CUDA thread 들을 동일한 갯수의 thread block 으로 분할한다.
- 예시
전체 thread 수 : 2 ^ 24
thread per block = 2 ^ 8 ( 256 ) 이라고 가정하면
총 block 수 = 2 ^ 24 / 2 ^ 8 = 2 ^ 16 개의 thread block 이 하나의 grid 안에 들어가 있는 것이다.
Kernel lauch 란 ?
Host (cpu) 에서 kernel 수행 명령을 내린다.
당연하게도 cpu 가 GPU 에게 일을 지시하는 부분이 있을 것이고 이게 그부분이다.
CombineTwoArraysKernel<<<dimGrid, dimBlock>>>(d_A, d_B, d_C);
이때 넘기는 정보는 두 가지다
(1) 커널 함수 이름 + 인자
(2) grid/block dimension. 이 한 줄이 GPU에 "이 함수를 이 구조로 병렬 실행해라"는 명령.
Combine... : GPU 에서 돌릴 함수 이름
dimGrid : block 이 몇개 필요한지
dimBlock : block 당 thread 를 몇개 둘껀지 ?
뒤 : 커널 인자
이런식으로 명령을 보통 준다. 그래서 host(cpu) 가 단순하게 커널(함수) 호출 하는게 아니라
GPU 에서 어떤 구성을 할지 같이 넘겨주는 식이다.

계속해서 설명했던 부분이라 크게 어렵지는 않지만 매우 중요한 내용이다.
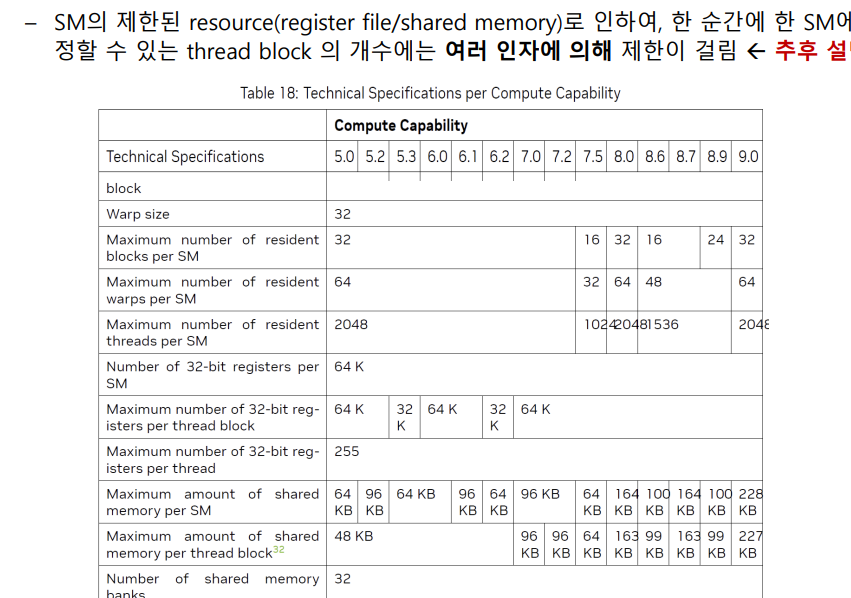
SM 은 무한히 많은 block 을 가질수는 없다.
SM 에 배정할 수 있는 thread block 수가 제한이 걸리는데 대략 4가지 정도 이유를 설명해 보겠다.
1. SM 당 최대 resident block 수
하드웨어 마다 SM 당 최대 몇개의 block 을 가질 수 있는지 상한선이 정해져 있다.
2. SM 당 최대 thread ( resident warp ) 수
SM 당 최대 48 warp 를 가질 수 있다 ( 숫자는 변동 가능 )
예를들어서.
block size = 256 / threads = 8 warps
→ 48 / 8 = 6 blocks 가능 (warp 제한)
→ min(6, 16) = 6 blocks
block size = 64 / threads = 2 warps
→ 48 / 2 = 24 blocks 가능 (warp 제한)
→ min(24, 16) = 16 blocks (block 상한에 걸림)
block size = 1024 / threads = 32 warps
→ 48 / 32 = 1 block (warp 제한)
→ min(1, 16) = 1 block
3. Register 용량
SM 당 레지스터 파일은 64K 32-bit 로 고정이 되어 있는데 , 이걸 SM 에 올라간 모든 thread 들이 나눠 써야한다.
커널이 컴파일되면 thread 당 레지스터 사용량이 결정되고 , 이게 block 수를 제한할 수 있다.
thread당 레지스터 = 40개
block size = 256 threads
→ block 하나가 필요한 레지스터 = 256 × 40 = 10,240개
→ 65,536 / 10,240 = 6.4 → 6 blocks (내림)
thread당 레지스터 = 96개 (Occupancy Calculator 예시)
block size = 256 threads
→ 256 × 96 = 24,576개
→ 65,536 / 24,576 = 2.67 → 2 blocks
두 번째 경우 레지스터 때문에 2개 block밖에 못 올려. warp로는 16개(2×8)뿐이니까 occupancy = 16/48 = 33%. 슬라이드 24의 Occupancy Calculator에서 "Limited by Registers per Multiprocessor" 라고 빨간색으로 뜨는 게 바로 이 상황이야.
thread당 레지스터를 줄이면 더 많은 block이 올라가지만, 레지스터가 부족하면 register spill — 레지스터에 못 담는 변수가 local memory(실제로는 global memory)로 넘어가서 성능 급감. 그래서 이것도 trade-off야.
4. Shared Memory 용량
SM 당 shared memory 도 정해져있다 (당연하게도) . 그래서 이런 부분도 신경써야한다.
shared memory 많이 쓰면 특정 부분의 최적화에 유리하지만 , shared memory 는 L1 Cache 와 같은 공간을 사용하는데 이때문에 resident block 수가 줄어 들 수 있다 ( 3번 참고 ).
shared memory 를 안쓰는 경우에 occupancy 는 높아지지만 , 반대로 global memory 접근이 많아져서 이때는 bandwidth bottleneck이 심해진다.
실제 SM 에 올라가는 block 수는 4가지 중에 가장 작은 값으로 결정된다고 보면 된다.
resident blocks = min(
하드웨어 max block 수, ← ①
max_warps / (block당 warp 수), ← ②
총 registers / (block당 register),← ③
총 shared_mem / (block당 smem) ← ④
)

Thread Blcok Processing
계에속 설명 했듯이 block 은 다시 warp 단위로 쪼개진다.
block 이 SM 에 올라가도 실제 처리 단위는 "warp" 이다.
반복 내용들은 제외를 하고 여기서 볼만한 점은
서로 다른 block 의 warp 가 섞여서 처리될 수 있다는 점이다.
한 SM 안에 여러 block 이 올라올 수 있으므로 , 서로 다른 block 에서 생성된 warp 들이 혼재되어서 처리될 수 있다.
예를들어서 한 SM 안에 block 0 , 1 이 resident 하다면 , warp scheduler 는 이 둘을 섞어서 실행할 수 있다.
다만, 같은 block 안의 warp 도 "순서" 를 지정하는 것은 불가능하다. 이는 스케줄러가 알아서 처리하는 부분이다.
또 warp 간 "자동 동기화" 는 없다.
다만 같은 block 내부의 warp 끼리는 shared memory 를 통해서 동기화가 가능하게 설정할 수 는 있다.
단 , 절대로 " block 간 " 동기화는 이루어 지지 않는다. 이는 cuda 프로그래밍 철칙에 어긋난다.

가장 중요한 개념은
" warp 가 GPU 의 가장 기본적인 SIMT processing unit " 이라는 점이다.
우리가 CUDA 코드를 thread 기준으로 작성하더라도 , 하드웨어가 실제로 잡아서 실행을 하는 단위는 warp 이다.
따라서 이 warp 를 얼마나 잘 활용하느냐가 cuda 프로그래밍에서 중요한 포인트가 될 것이다.
그림을 설명해 보자면 다음과 같다.
1. TB ( 0 , 1 ,,,, P )
thread block 이다. kernel launch 하면 grid 안에 block 들이 저런식으로 생길 것이다.
예 : kernel<<<gridDim, blockDim>>>(...);
그러면 gridDim 만큼 block 이 생기고 , blockDim 만큼 하나의 thread block 안에 thread 가 존재할 것이다.
다만 여기서 , block 들이 한번에 전부 동시에 실행 되는 것이 아니라
일부가 SM 에 올라가고 , 나머지는 기다리는 식이다.
2. GPU scheduler
여기서 GPU scheduler 는 전체 grid 의 block 들을 보고 어떤 SM 에 올릴지 결정하는 역할이다.
다만 이부분은 알아서 정해주는 부분이라 우리가 컨트롤 할 수 있는 영역은 아니다.
여기서 중요한 부분은
block scheduling
- block 은 SM 단위로 배정된다.
- 어느 block 이 어떤 SM 으로 갈지는 프로그래머가 직접 정하지는 않는다.
- block 은 독립적으로 실행된다.
정도만 알고있으면 충분하다.
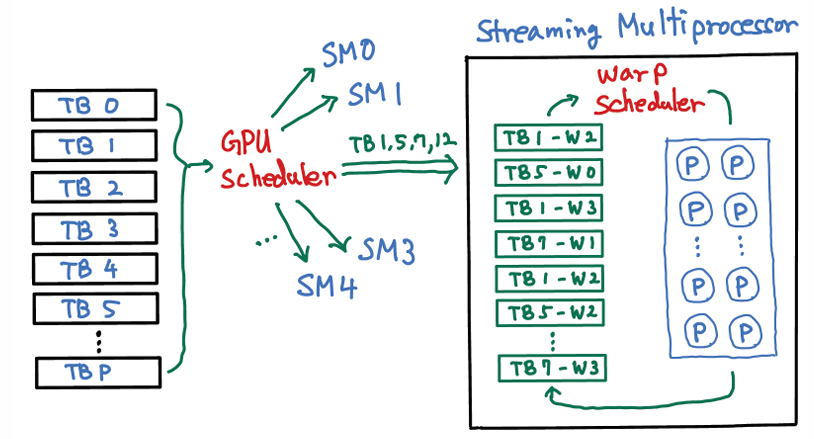
3. SM 내부
가장 오른쪽 박스가 SM ( streaming Multiprocessor ) 를 나타낸다.
여러가지 TB 가 있고 , 이중에서 TB 1 ,5 ,7 , 12 가 하나의 SM 에 들어왔다고 가정을 해보자.
그럼 그 블록들이 resident 한 상태이다.
또 , 다른 thread block ( TB ) 에서 나온 WARP 들이 같은 SM 에 존재할 수 있다.
여기서 나도 살짝 의아했던 부분이
TB1 - w2
TB5 - w2
이게 왜 같이있지? 라고 생각했었고 warp 가 그러면 겹치는건가 ? 이렇게 생각해서 의아했었는데
이건 그냥 다른 thread block 에서 나온 warp 이다.
그니까 쉽게말해서
"TB1 에 속한 WARP 2" 이니까 TB5 에서도 그냥 똑같이 자른 것중에서 두번쨰 WARP 인것이다. ( 중요한건 아니다 )
[ warp pool ] 이라는 개념이 여기 있는데 별건 아니고
SM 안에 지금 resident 한 block 들이 있고 , 해당 블록들에서 나온 warp 들이 여러개 대기하고 있는데
대기중인 warp 집합을 슬라이드 에서는 warp pool 로 표현한 것이다.
그래서 나중에는 스케줄러가 이들 중에서 실행 가능한 warp 들을 골라서 연산 연산 하는 곳으로 보낸다 ( tensor / cuda 아마도. )
4. warp 내의 32 개 thread 들을 SIMT 형태로 처리
SIMT = "Single Instruction , Multiple Threads"
- warp 안에 32개 thread 있고
- 안에 thread 들은 같은 instruction 따라가면서
- 각자 자기 데이터 처리함.
그니까 명령은 같고 데이터만 같다고 이해하면 된다.
5. Zero-cost context switching
다시 중요한 내용이다. 한 processing block 에 배정된 warp 가 global memory 에 접근해야할 일이 있을 수 있다. 그러면 access 가 느리기 때문에 해당 warp 때문에 다른 처리를 못하고 기다려야 하는 상황이 올 수 있다. 따라서 이런 상태를 stall ( 대기 ) 라고 생각하면 된다.
이를 해결하고자 GPU 에서는 zero-cost context switching 을 한다.
CPU 에서는 thread 를 바꾸는게 상대적으로 무거운데
GPU 에서는 애초에 SM 안에 warp 의 상태를 다 가지고 있기 때문에 context switching 의 cost 가 사실상 zero 에 가깝다 .
( program counter / register context / warp state - on chip 으로 가지고 있다. )
그래서 warp A 가 stall 상태에 있으면 바로 다른 warp 를 집어 넣으면 된다.
이를 zero-cost context switching 이라고 부른다.
hiding memory latency with ALU operations
결국 연결되는 이야기인데 , zero-cost context switiching 을 하니까 사실상 GPU 메모리는 latency 를 매우 잘 숨길 수 있다.
warp A 가 기다리는 동안 warp B 를 돌리고 , 다시 global memory access 하면 warp A 돌리고 ....
이런식으로 기다리는 시간을 숨기면 된다.
그래서 멀리서 보면 SM 이 쉬지않고 일 하는 것 처럼 보이고 이게 latency hiding 이다.
또 마지막으로 그래서 warp 를 많이 resident 하게 두면 좋은점이 이와 관련이 있는데 ,
warp 가 여러개 SM 에 존재하면 더 memory latency 를 가릴 여지가 커진다.
따라서 warp 를 얼마나 SM 에 잘 띄울 수 있냐 가 프로그래머에게 중요한 포인트이다.
Warp Occupancy

계속 반복되는 이야기 이지만 GPU 는 thread 하나씩 보는게 아니라 , warp ( 32개 thread 묶음 ) 단위로 보아야한다.
occupancy 를 대략적으로 이야기 해보자면 " SM 안에 지금 대기/상주 하고 있는 warp 가 얼마나 되는가 ? " 에 대한 이야기 이다.
조금 더 정확히는 위의 자료 그대로
' 동시에 active한 warp 수 / 그 SM이 가질 수 있는 최대 warp 수 ' 이다.
그렇다면 occupancy 가 왜 중요한가 ?
이전에도 이야기 했지만 GPU 가 memory latency 를 숨기는 핵심 메커니즘이 warp 간 zero-cost context switching 인데 , warp 가 메모리 접근 ( 시간이 오래 걸리는 동작 ) 으로 stall 되면 , warp scheduler 가 바로 ready 상태의 warp 를 실행시켜서 파이프라인을 채운다. 근데 SM 에 올라와 있는 warp 수가 적으면 교체할 warp 가 줄어들고 , 그러면 poor instruction issue efficiency 가 된다.
occupancy 가 높으면 항상 좋은가 ?
ccupancy가 충분히 높아져서 latency hiding이 이미 되는 상태라면, 그 이상 더 높인다고 항상 좋은 게 아니다. 오히려 thread당 쓸 수 있는 resource가 줄어서 성능이 나빠질 수도 있다. ( 그니까 적절히 잘 설계 해야한다 . 적절하다는건 늘 어렵다 )
( Better Performance at Lower Occupancy 라는 논문을 참고해보자. -> 간단하게 이야기 해보면 낮은 occpancy 에서도 높은 성능을 달성했다는 뜻. occpancy 도 결국 latency hiding 의 한가지 수단이고 다른 방식도 고려해야한다는 주장을 펼친다. )
Occpancy 를 제한하는 것들
이부분도 이전에 설명이 어렴풋이 나왔는데 , 보통 핵심 제안 요소는 4가지이다.
- max resident blocks per SM
- max resident threads / warps per SM
- registers per SM
- shared memory per SM
그리고 커널 쪽에서는:
- block size (threads per block)
- registers per thread
- shared memory per block
이 자원을 얼마나 쓰는지 중요하다.
thread block 은 warp 로 쪼개지는데 ( warp = 32 thread )
block 하나를 SM 에 올리면 해당 block 의 warp "전체" 가 SM 자리를 차지한다.
만약에 애매하게 걸쳐서 warp 를 전체다 SM 에 한번에 올리지 못하는 경우에 아마 좋지 못한 성능을 낼 것이다.
반대로 block 이 너무 작아도 , block 갯수에 제한이 있기 때문에 충분히 채우지 못할 수도 있다.
이 둘을 고려해서 적절히 해야한다.
Synchronization within a Thread Block

왜 synchronization 이 필요한가 ?
GPU 는 Thread 를 아주 "많이 " "동시" 에 돌린다. 하지만 같은 thread block 안의 스레드들도 같은 속도로 실행이 보장되지는 않는다. 결국 thread 마다 제각기 다른 step 을 밟고 있을 확률이 매우매우 높고 이부분은 우리가 어떻게 할 수 있는 부분은 아니다 ( 스케줄러가 알아서 처리하는 부분이다. )
그래서 thread 간에 데이터를 주고 받으려면 "동기화" 가 필수로 필요하다.
** 헷갈림 주의
Thread block 안에서 동기화 ( 같은 thread block 내의 warp 사이의 동기화를 이야기 하고 있다. )
여전시 thread blocks 간 동기화는 다루지 않고 있다.
__syncthreads(): Block-level Barrier
__syncthreads()는 같은 thread block 안의 모든 non-exited thread가 해당 지점에 도달할 때까지 기다리는 barrier다
- 같은 block 의 thread 사이의 조율을 담당한다
- 같은 intrinsic call 에 모든 (non-exited) thread 가 도달하거나 , exit 할떄 까지 기다린다.
어렵게 생각할 필요 없이 thread 간에 처리 단계의 차이가 있는데 , 이걸 막기 위해서 모두 같은 단계까지 기다리게 하는 것이다.
하지만 이렇게 단순하게 대기만이 아니라 memory visibility 도 보장한다
Memory visibility
barrier 이전의 global/shared memory access가 block 내 모든 thread에 visible하다. 이게 또 중요한 포인트이다.
thread A,B 가 있는데
thread A 가 shared memory 에 쓴 값
thread B 가 barrier 뒤에서 읽는 값
둘간의 관계가 안전해진다.
만약에 barrier 가 없으면 함수를 실행하다보면 thread 간 속도 차이 때문에 오류가 생길 수 있는 부분을 방지할 수 있다.
(Programing Guide 공식 문서 참고)
예를들어서
shared memory 에서 이런 기능을 많이 사용한다. shared memory 를 같은 thread block 의 모든 thread 가 접근 가능한 on-chip memory 이고 , 안에서 data race 를 피하려면 __synthreads() 를 사용해야한다고 한다.
특히 한 thread가 합계를 읽기 전에 다른 thread들의 write가 모두 끝났음을 보장하기 위해 barrier를 둔다.
__shared__ float buf[256];
buf[threadIdx.x] = some_value;
__syncthreads();
float x = buf[threadIdx.x ^ 1]; // 다른 thread가 쓴 값 읽기
만약에 __syncthreads() 를 사용하지 않고 다른 idx 에 접근하면 거기서부터 race 가 생긴다.
이처럼 shared memory 를 공동 작업장 처럼 쓰는 패턴에서는 barrier 가 반드시 들어가야 한다.
예시 )

주석은 내가 이것저것 참고해서 단거라 정확하지 않을 수 있지만 , 이런 류의 코딩은 지금 거의 처음이라 이해가 살짝 더디다.
그래도 너무 벗어난 내용들은 아니고 , 결국 "동기화" 를 어떻게 잘해줄 것이냐의 문제이다.
__syncthreads() → 블록 전체 512개 스레드가 여기서 만남
__syncwarp() → 내가 속한 warp 32개 스레드만 여기서 만남
이런식으로 어떤걸 동기화 할지도 고려해가면서 코드를 작성해야되는 것 같다.
기본 셋팅 설명 ( with gpt )
좋아. 이 코드는 처음 보면 되게 난잡해 보이는데, 사실 하고 싶은 일은 아주 단순하다.
블록 하나가 맡은 데이터들을 다 더해서, block당 결과 1개를 y[blockIdx.x]에 저장하는 것
즉 reduction(합 축소) 예제다.
슬라이드 코드도 reduce4(float* y, float* x, int N) 형태로 되어 있고, block 안에서는 tsum[]라는 shared memory를 써서 합을 줄여 나간다. 앞부분은 __syncthreads(), 마지막 warp 구간은 __syncwarp()를 쓴다.
0) 먼저 전체 그림
이 커널은 한 번에 최종합을 바로 만드는 커널이라기보다,
- 입력 x의 일부를
- 각 block이 자기 몫만 먼저 더해서
- y[blockIdx.x]에 partial sum(부분합) 을 저장하는 구조다.
즉 block이 여러 개면 결과 y도 여러 개 나온다.
x 전체 데이터
↓
block 0 → 부분합 y[0]
block 1 → 부분합 y[1]
block 2 → 부분합 y[2]
...
그래서 이 커널 하나만으로 최종합이 끝날 수도 있고,
아니면 y를 다시 reduce하는 다음 단계 커널이 또 필요할 수도 있다.
1) 코드에서 변수들이 뭔지부터
슬라이드 코드의 앞부분은 이렇다.
__global__ void reduce4(float* y, float* x, int N) {
extern __shared__ float tsum[];
int id = threadIdx.x;
int tid = blockDim.x * blockIdx.x + threadIdx.x;
int stride = gridDim.x * blockDim.x;
이걸 하나씩 보면:
tsum[]
extern __shared__ float tsum[];
- shared memory 배열
- 같은 block 안 thread들이 같이 쓰는 scratchpad
- launch할 때 크기를 정해준다
- 슬라이드 launch 문에서 세 번째 인자가 threads * sizeof(float)인데, 이게 바로 tsum 크기다.
즉 thread가 256개면:
tsum[0] ~ tsum[255]
까지 생긴다고 보면 된다.
id = threadIdx.x
- block 내부 local thread 번호
- 0, 1, 2, ..., blockDim.x-1
예를 들어 blockDim.x=256이면 id는 0~255다.
tid = blockDim.x * blockIdx.x + threadIdx.x
- grid 전체 기준 global thread 번호
예를 들어 block 크기가 256이면:
- block 0의 thread 0 → tid 0
- block 0의 thread 1 → tid 1
- ...
- block 1의 thread 0 → tid 256
- block 1의 thread 1 → tid 257
이런 식이다.
stride = gridDim.x * blockDim.x
- grid 전체에 있는 총 thread 수
- grid-stride loop에서 다음에 내가 맡을 index로 점프할 간격이다.
예를 들어:
- blocks = 80
- threads = 256
이면
[
stride = 80 \times 256
]
이다.
2) launch 문도 같이 이해해야 한다
슬라이드 맨 아래 launch는 이거다.
reduce4<<<blocks, threads, threads * sizeof(float)>>>(d_B, d_A, N);
이 triple chevron에서:
- 첫 번째 blocks = block 개수
- 두 번째 threads = block당 thread 개수
- 세 번째 threads * sizeof(float) = dynamic shared memory 크기
즉 tsum은 block마다 threads개짜리 float 배열로 만들어진다.
Programming Guide도 dynamic shared memory는 launch의 세 번째 인자로 바이트 수를 주고, 커널 안에서는 extern __shared__로 선언한다고 설명한다.
3) 제일 먼저 하는 일: 각 thread가 자기 local sum 만들기
코드:
tsum[id] = 0.0f;
for (int k = tid; k < N; k += stride)
tsum[id] += x[k];
__syncthreads();
이 부분이 중요하다.
( cf. 여기서 stride = 전체 스레드수 를 말하는 것이다. )
의미
각 thread는 입력 x에서 한 원소만 처리하는 게 아니라,
k += stride로 점프하면서 여러 원소를 자기 혼자 먼저 더한다.
즉:
thread tid 는
x[tid], x[tid + stride], x[tid + 2*stride], ...
를 다 더해서 tsum[id]에 저장
이다.
이걸 grid-stride loop라고 부른다. 슬라이드도 그대로 그 형태를 쓰고 있다.
왜 이렇게 하냐
입력 N이 grid 전체 thread 수보다 훨씬 클 수 있기 때문이다.
그래서 각 thread가 일정 간격으로 여러 원소를 맡는다.
예시
예를 들어:
- blocks = 2
- threads = 4
- 그러면 전체 thread 수 = 8
- stride = 8
이면
- tid 0 → x[0], x[8], x[16], ...
- tid 1 → x[1], x[9], x[17], ...
- ...
- tid 7 → x[7], x[15], x[23], ...
이렇게 맡는다.
그리고 그 합을 각자 tsum[id]에 넣는다.
4) 왜 여기서 __syncthreads()를 하나
첫 번째 barrier:
__syncthreads();
이건 block 안 모든 thread가 자기 local sum을 tsum[]에 다 써놓을 때까지 기다리자는 뜻이다.
__syncthreads()는 같은 block의 모든 non-exited thread가 같은 위치에 도달할 때까지 기다리고, 그 이전의 shared/global memory access가 block 안 다른 thread에게 visible하게 만든다.
즉 여기서의 의미는:
이제부터는 남이 쓴 tsum[...]도 읽을 건데,
그 전에 전부 다 write 끝내고 오자.
이다.
5) 그다음은 “반씩 줄여가며 더하기”다
이제부터 reduction이 시작된다.
if (id < 256 && id + 256 < blockDim.x)
tsum[id] += tsum[id + 256];
__syncthreads();
if (id < 128)
tsum[id] += tsum[id + 128];
__syncthreads();
if (id < 64)
tsum[id] += tsum[id + 64];
__syncthreads();
슬라이드 그대로다.
이건 pairwise reduction tree다.
핵심 아이디어
처음엔 tsum에 thread 개수만큼 값이 있다.
예를 들어 blockDim.x = 256이면:
tsum[0], tsum[1], tsum[2], ... tsum[255]
이렇게 256개가 있다.
이걸:
- 256개 → 128개
- 128개 → 64개
- 64개 → 32개
- 32개 → 16개
- 16개 → 8개
- 8개 → 4개
- 4개 → 2개
- 2개 → 1개
로 줄여 가는 것이다.
6) 왜 if (id < 256) tsum[id] += tsum[id + 256] 같은 형태인가
이건 “앞 절반 thread만 살아남아서 뒤 절반 값을 자기 자리로 끌어와 더한다”는 뜻이다.
예를 들어 blockDim.x = 512면 처음엔 512개 값이 있다.
0 1 2 ... 255 | 256 257 258 ... 511
이때
if (id < 256)
tsum[id] += tsum[id + 256];
를 하면:
- thread 0 → tsum[0] += tsum[256]
- thread 1 → tsum[1] += tsum[257]
- ...
- thread 255 → tsum[255] += tsum[511]
이 된다.
그러면 이제 의미 있는 값은 앞 256개 칸에만 남고, 뒤쪽은 버려도 된다.
즉:
512개 값 → 256개 값으로 축소
가 된다.
7) 왜 매 단계마다 __syncthreads()를 또 하나
이게 제일 중요하다.
예를 들어:
if (id < 128)
tsum[id] += tsum[id + 128];
__syncthreads();
여기서 thread 0이 tsum[128]을 읽으려면,
그 tsum[128] 값은 이전 단계에서 thread 128이 이미 계산해서 써놓았어야 한다.
그런데 GPU thread들은 완전히 같은 속도로 줄 맞춰 달리는 게 아니므로,
어떤 thread는 이미 다음 줄에 왔고, 어떤 thread는 아직 이전 줄 계산 중일 수 있다. 그래서 block-level barrier가 필요하다. 슬라이드도 __syncthreads()를 같은 block thread들 사이 communication 조율용 barrier로 설명한다.
즉 단계마다 barrier를 두는 이유는:
이전 단계 결과가 다 써진 뒤에야 다음 단계가 읽게 하려는 것
이다.
8) 아주 작은 장난감 예제로 reduction 감각 잡기
실제 코드는 32/64/128/256 단위지만,
직관을 위해 8개 값만 있다고 생각해보자.
처음:
tsum = [3, 1, 4, 2, 5, 6, 7, 8]
1단계: 앞 절반이 뒤 절반을 더함
tsum[0] += tsum[4] → 3+5 = 8
tsum[1] += tsum[5] → 1+6 = 7
tsum[2] += tsum[6] → 4+7 = 11
tsum[3] += tsum[7] → 2+8 = 10
이후:
[8, 7, 11, 10, -, -, -, -]
2단계
tsum[0] += tsum[2] → 8+11 = 19
tsum[1] += tsum[3] → 7+10 = 17
이후:
[19, 17, -, -, -, -, -, -]
3단계
tsum[0] += tsum[1] → 19+17 = 36
최종합:
tsum[0] = 36
지금 슬라이드 코드는 이걸 실제 warp 단위에 맞춰 512→256→128→64→32→16→8→4→2→1 식으로 한 것이다.
9) 여기서 왜 __syncthreads()는 64까지 쓰고, 그 뒤는 __syncwarp()인가
슬라이드에 이렇게 적혀 있다.
if (id < 64) tsum[id] += tsum[id + 64];
__syncthreads();
// warp 0 only from here
if (id < 32) tsum[id] += tsum[id + 32];
__syncwarp();
...
이 말의 핵심은:
64까지는 여러 warp가 같이 관여한다.
32부터는 warp 0 하나만 남는다.
이다.
blockDim.x = 256이라고 생각해보자
256 threads = 8 warps다.
- warp 0: id 0~31
- warp 1: id 32~63
- warp 2: id 64~95
- ...
- warp 7: id 224~255
if (id < 64)
이 단계는 id 0~63이 일한다.
즉 warp 0, warp 1 두 개가 관여한다.
그래서 이 단계 뒤에는 warp 간 동기화가 필요하다.
따라서 __syncthreads()를 쓴다. __syncthreads()는 block 전체 barrier다.
if (id < 32)
이제부터는 id 0~31만 일한다.
즉 warp 0 한 개만 관여한다.
이제는 block 전체를 기다릴 필요가 없다.
warp 0 내부 thread들끼리만 맞추면 되므로 __syncwarp()를 쓴다. 슬라이드도 __syncwarp()는 warp 내부 communication을 위한 barrier이고, __syncthreads()보다 훨씬 가볍다고 설명한다.
10) 그런데 왜 warp 안에서도 sync가 필요한가
이 포인트가 pg.34~37과 연결된다.
예전에는 warp 안 thread들이 lock-step처럼 같이 움직인다고 생각하는 코드가 어느 정도 통했지만, Volta(CC 7.0) 이후에는 Independent Thread Scheduling 때문에 warp 안 thread들도 더 독립적으로 전진할 수 있다. 슬라이드는 Before Volta는 warp가 single PC/call stack으로 lock-step이고, Since Volta는 각 thread가 own instruction address counter와 register state를 가져 더 독립적으로 진행할 수 있다고 설명한다.
그래서 warp 내부에서
- 어떤 thread가 값을 shared memory에 쓰고
- 다른 thread가 바로 다음 줄에서 그 값을 읽는
패턴이면, 이제는 __syncwarp()로 명시적으로 맞춰 주는 게 안전하다. __syncwarp()는 같은 warp의 participating thread 사이 memory ordering을 보장한다.
즉 슬라이드의 마지막 구간은 단순히 “warp니까 알아서 되겠지”가 아니라,
warp 0 내부 reduction도 memory communication이 있으니, 명시적으로 __syncwarp() 넣자
라는 의미다.
11) 마지막 부분은 왜 저렇게 끝나나
코드 마지막:
if (id < 2) tsum[id] += tsum[id + 2];
__syncwarp();
if (id == 0)
y[blockIdx.x] = tsum[0] + tsum[1];
슬라이드 그대로다.
많이 헷갈리는 부분인데, 왜 마지막에 그냥 tsum[0]을 쓰지 않고 tsum[0] + tsum[1]을 하냐?
이유는 reduction을 완전히 1개 값으로 만들기 직전 단계까지만 코드로 썼기 때문이다.
즉 직전 상태는 대략:
tsum[0], tsum[1]
두 개가 살아 있는 상태고,
마지막 한 번을 thread 0이 직접
tsum[0] + tsum[1]
로 해서 output에 저장한다.
즉 이 줄은 사실상 “마지막 reduction 한 번 더”다.
12) 전체 흐름을 한 번에 다시 그려보면
이 코드의 논리는 이렇게 보면 된다.
단계 A. 각 thread가 global memory에서 자기 local sum 생성
x 여러 원소들
↓
thread 0 → local sum
thread 1 → local sum
thread 2 → local sum
...
각 결과를 tsum[id]에 저장.
단계 B. block 내부 shared memory reduction
tsum[0..blockDim-1]
↓
절반씩 줄임
↓
64개
↓
32개
64까지는 여러 warp가 섞여 있으니 __syncthreads().
단계 C. 마지막 warp만 남음
32개
↓
16개
↓
8개
↓
4개
↓
2개
↓
1개
여기는 warp 0만 관여하므로 __syncwarp().
단계 D. block 결과 저장
y[blockIdx.x] = block partial sum
13) 이 코드에서 꼭 기억해야 하는 포인트
포인트 1: tsum[]은 shared memory다
같은 block 안 thread들이 공동으로 쓰는 공간이다.
그래서 barrier 없이 읽고 쓰면 race/hazard가 날 수 있다.
포인트 2: __syncthreads()는 block 전체 barrier다
같은 block의 모든 non-exited thread가 도달할 때까지 기다리고, 이전 memory access를 block 내 다른 thread에게 보이게 한다.
포인트 3: __syncwarp()는 warp 내부 barrier다
warp 내부 communication용이다. Volta 이후에는 warp 안도 필요할 때 explicit sync가 필요하다.
포인트 4: 64까지 __syncthreads(), 32부터 __syncwarp()
이유는 “여러 warp가 아직 살아 있느냐 / 이제 한 warp만 남았느냐” 차이다.
포인트 5: 이 커널 결과는 block당 1개
즉 y[blockIdx.x]는 최종 global sum이 아니라 partial sum이다.
14) 네가 지금 가장 헷갈려하면 안 되는 부분만 딱 찌르면
이 예제의 본질은 사실 아래 한 줄이다.
“여러 thread가 각자 계산한 값을 shared memory에 모아 놓고, 그 값을 단계적으로 합칠 때, 여러 warp가 섞이는 구간은 __syncthreads(), 마지막 한 warp만 남는 구간은 __syncwarp()를 쓴다.”
이걸 reduction 예제로 보여준 것이다.
15) 마지막으로, 이 코드를 네 머릿속에 제일 쉽게 넣는 비유
각 thread를 학생이라고 생각해보자.
- 처음엔 학생마다 자기 시험지 여러 장을 먼저 채점해서
개인 점수를 만든다
→ for (...) tsum[id] += x[k]; - 그다음 둘씩 짝지어서 점수를 합친다
→ reduction - 이때 여러 조가 동시에 움직이면
“다 끝나고 다음 라운드로 넘어가”
가 필요하다
→ __syncthreads() - 마지막엔 한 조(=한 warp) 안 학생들만 남으니까
이제 반 전체를 세울 필요는 없고
그 조 안에서만 맞추면 된다
→ __syncwarp()
이렇게 생각하면 된다.
원하면 다음 답변에서는 내가 이 코드를 blockDim.x = 256 기준으로 id=0,1,2,...가 실제로 어떤 값을 읽고 쓰는지 표처럼 한 단계씩 완전히 펼쳐서 보여주겠다.
cf.
// 여기는 스레드 0~255가 일함 → Warp 0~7이 관여 → 여러 warp
if (id < 256) tsum[id] += tsum[id + 256];
__syncthreads(); // 여러 warp 기다려야 하니까 무거운 동기화
// 여기는 스레드 0~31만 일함 → Warp 0 하나만 관여
if (id < 32) tsum[id] += tsum[id + 32];
__syncwarp(); // warp 하나니까 가벼운 동기화로 충분
-> warp 안에서도 동기화가 안되기 떄문에 ( 기본적으로 ) 처렇게 index 참조하는 경우에 이상해질 수 있다. 따라서 하나의 warp 안에서도 반드시 이런식으로 동기화를 해서 관리를 해줘야 문제가 생기지 않는다.
- 앞부분은 여러 warp가 같이 살아 있다
→ block-level sync 필요 - 마지막엔 warp 0 하나만 남는다
→ block 전체 sync는 과하다
→ warp 내부만 맞추면 된다
- 여러 warp가 협업할 때 → __syncthreads()
- 이제 한 warp 안에서만 협업할 때 → __syncwarp()
라고 보면된다.
__syncthreads() 적용 범위 : 같은 block 만.
위에서 설명했던 내용 처럼 우리는 계속 " 같은 블럭 " 을 기준으로 동기화 하는 것을 보고 있다.
block 0 와 block 1 은 전혀 서로가 뭘 하는지 알 수 없다. CUDA 의 기본 execution model 에서는 각 block 이 논리적으로 독립적이고 , block 간 scheduling 순서 보장이 없다.

Conditional 안에서 쓸 떄 조심해야한다.
__syncthread() 가 conditional code 안에서도 허용은 되나 , 조건이 thread block 전체에서 동일하게 평가될 경우만 안전하다.
그렇지 않으면 deadlock 이나 , unintended side effects 가 발생할 수 있다.
예를 들어 이건 위험하다.
__syncthreads();
}
왜냐하면:
- threadIdx.x < 64인 thread만 barrier에 들어감
- 나머지 thread는 barrier에 안 들어감
그럼 barrier에 들어간 thread들은 “block 전체가 올 때까지 기다려야 하는데”
나머지는 영원히 안 오므로 멈춰버린다. -> 즉 deadlock.
( 몇가지 케이스는 만들어서 확인좀 해보기 )
-> 여기서 좀 헷갈리는듯 예시는 클로드나 뭐 이런걸로 좀 만들어서 시험때 조심하기
라고 한다. 대충 참고.
비유: 회전문
__syncthreads()는 512명이 다 모여야 열리는 회전문이야.
케이스 1: 전원이 같은 길로 감
if (N > 1000) {
// ... 계산 ...
__syncthreads(); // 회전문
}
N=2000이면:
512명 전원: "N 크네? 이쪽 길로 가자"
→ 전원 회전문 도착
→ 512명 다 왔네 → 열림 ✅
케이스 2: 갈림길에 회전문을 놓음
if (threadIdx.x < 128) {
__syncthreads(); // 회전문을 왼쪽 길에만 놓음
}
0~127번: "왼쪽 길로 갈게" → 회전문 도착 → "512명 와야 열린대..."
128~511번: "오른쪽 길로 갈게" → 회전문 안 만남 → 그냥 지나감
왼쪽 128명: 영원히 기다림 💀
케이스 3: 양쪽 길에 각각 회전문
if (threadIdx.x < 256) {
__syncthreads(); // 회전문 A
} else {
__syncthreads(); // 회전문 B
}
이것도 데드락이야:
0~255번: 회전문 A 도착 → "512명 와야 열린대..." → 256명밖에 없음 💀
256~511번: 회전문 B 도착 → "512명 와야 열린대..." → 256명밖에 없음 💀
회전문 A와 B는 다른 회전문이야. A에 256명, B에 256명 와봤자 소용없어. 각 회전문이 각각 512명을 기다림.
케이스 4: 올바른 패턴
if (threadIdx.x < 256) {
tsum[id] += tsum[id + 256]; // 일부만 계산
}
__syncthreads(); // 회전문은 길이 합쳐진 곳에 놓음
0~255번: 계산하고 나옴
256~511번: if 건너뜀
전원 회전문 도착 → 512명 다 왔네 → 열림 ✅
이게 reduce 코드에서 쓴 패턴이야. 계산은 일부만, 동기화는 전원이.
위의 내용과 비슷한 결인데 , non-exited threads 의미
- 이미 함수에서 return 해버린 thread 는 barrier 대상이 아니고
- 살아있는 thread 기리는 "모두" barrier 에 도달해야한다. ( 특히 예시를 보면 if - else 문에 서로 동기화를 하는 것 처럼 보이지만 , 이것도 결국 하나의 sync 에서 다 모여야 하는거라 오류다 )
< predicate variant >
- __syncthreads_count(int predicate);
- __syncthreads_and(int predicate);
- __syncthreads_or(int predicate);
위 함수들은 barrier 역할 하면서 , predicate 결과를 추가로모아주는 함수들이다.
그래서 마지막으로 정리하면
같은 block의 thread들이 shared/global memory를 통해 협업할 때,
어느 시점 이전에 쓴 데이터가 이후에 안전하게 읽히도록,
전원이 한 지점에 도착할 때까지 묶어두는 장치가 __syncthreads()다.
라고 할 수 있겠다.
Extensions to the Classical CUDA Execution Model: Independent Thread Scheduling (Volta/CC 7.0 or Later)
Before Volta: warp 안 32개 thread가 거의 “한 몸처럼” lock-step으로 감
Since Volta: warp 안 thread들도 더 독립적으로 전진할 수 있음
→ 그래서 예전에는 암묵적으로 맞던 warp-synchronous 코드가 지금은 깨질 수 있음.
중요한 내용은 다음과 같고 좀 더 이것저것 자세히 살펴보도록 하겠다.
[ Before Volta ]
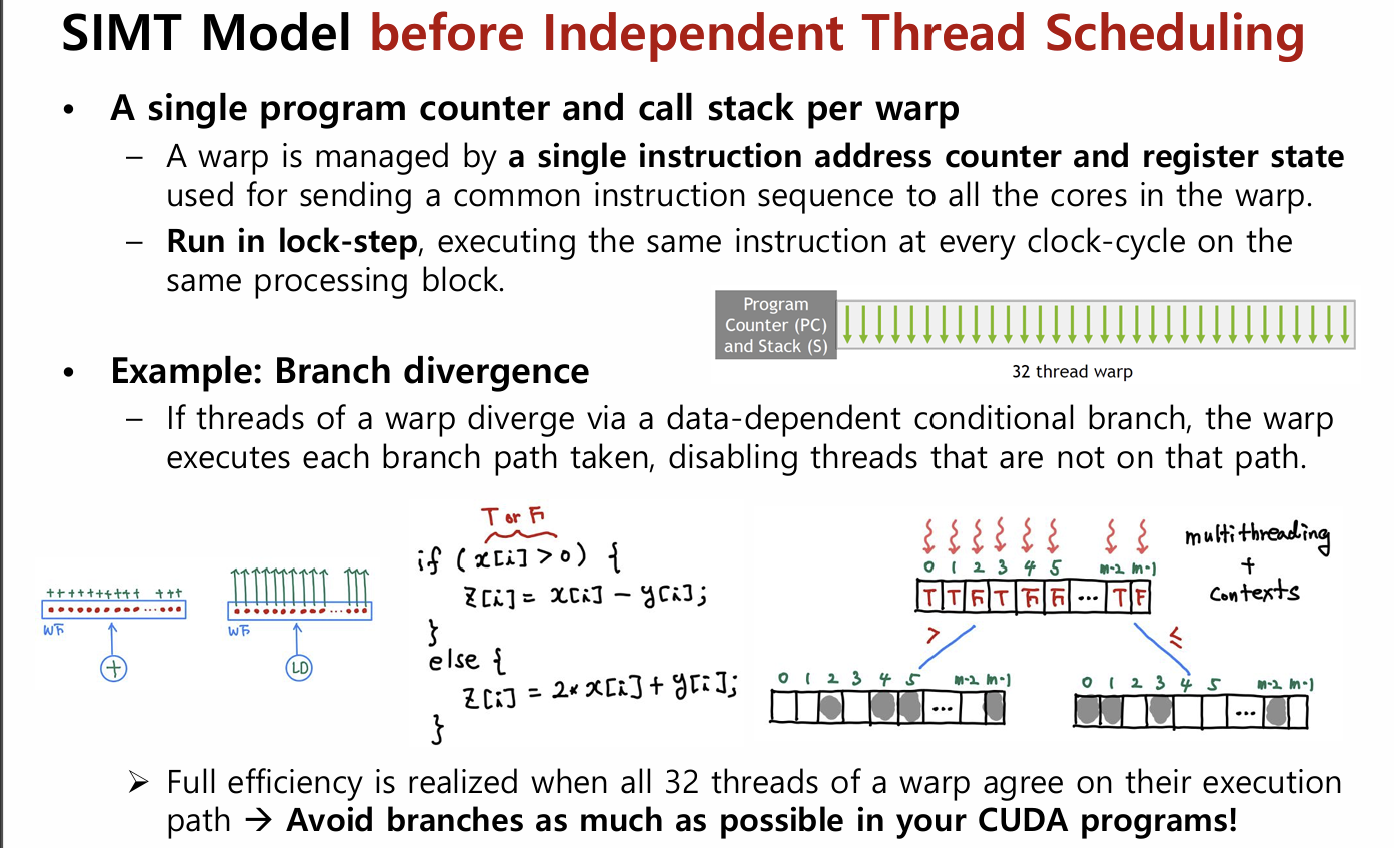
Before Volta 에서는 warp 안 32 thread 가 거의 한 몸 처럼 같이 움직였다. 즉 warp 마다 PC ( programing counter )와 call stack 이 1개였고 , 같은 instructin 을 lock - step 으로 실행했다. warp 는 32개의 thread 로 이루어져 있고 이게 GPU 의 기본 실행 단위이다.
" warp 당 PC 를 하나 " 이게 여기서 가장 핵심이다.
- Single PC and Call stack per warp
- 쉽게 말해서 PC 가 한개 밖에 없으니까 warp 32 개 스레드가 PC 를 공유하게 되고 , 그러면 32 개 스레드 모두 같은 명령을 수행하고 있을것이다 ( 코드에서 같은 줄을 보고 있으니까. )
- 그냥 같은 Warp 안 thread 들이 같은 thread 를 같이 하고있는걸 lock-step 이라고 한다.
- single instruction address counter & register state 로 관리된다.
- 각 스레드가 다루는 데이터는 다르다 ( 같은 줄이여도 ) , 그래서 명령어는 같지만 데이터 ( reigster 값 ) 은 다르다. ( 이걸 SIMT 라고 부르기도 하고 )
Example: Branch divergence

그렇다면 if 문 처럼 분기가 생기면 어떻게 처리할까 ?
warp 안 thread 들이 data-dependent conditional branch 때문에 갈라지게 되면 , warp 는 각 branch path 를 하나씩 실행하고 그 path 에 속하지 않는 thread 는 disable/inactivate 된다.
그니까 거기에 속하지 않는 thread 는 mask 처리해서 연산을 안하고 , 서로 따로 thread 를 실행시킨 다음에 합치면 된다.
( 현재 instruction 에 참여하는 thread = active / 아니면 inactive )
( warp 안 thread들이 같은 길로 갈수록 좋고, branch divergence가 많을수록 비효율 - 뭐 당연한거다 )


1) Only active threads of a warp participate in the current instruction
- 현재 instruction 실행하는건 active thread 뿐 ( 앞에서 말했던 내용 그대로 )
- acitve 가 되는 3가지 이유
- 어떤 thread 가 임지 return 하거나 작업이 끝나서 빠져나가고 , 같은 warp 의 다른 thread 는 실행중인 경우.
- 위에서 살펴봤던 if 문 떄문에 barnch 가 나눠져서
- warp 크기가 32 인데 , block 크기가 32의 배수가 아닌경우 . 그러면 마지막에 빈부분이 생길텐데 그부분은 inactive 처럼 취급한다.
2) Instructions are always synced between threads in a warp
warp 안에 thread 들은 instruction 수준에서는 항상 맞춰져 있다
왜 ? berfore volat 에서는 warp 가 single PC 와 call stack 을 공유하고 lock-step 으로 움직였기 떄문이다.
그래서 같은 warp 안 thread 들이 instruction 단위로 흩어질까 걱정해서 별도의 barrier 를 넣을 필요는 없다.
3) Memory operations may not be synced
하지만 memory 동기화는 필요하다. 같은 명령어를 실행해도 메모리에 쓰는 타이밍은 다를 수 있기 떄문이다.
예를들어서 이렇다.
// 라인 1: 32개 스레드 동시 실행 — 각자 자기 칸에 write
tsum[id] = my_value;
// 라인 2: 32개 스레드 동시 실행 — 남의 칸을 read
float x = tsum[31 - id]; // 스레드 0은 tsum[31]을 읽음
// 근데 스레드 31의 write가 아직 메모리에 안 도착했을 수도!
명령어 자체는 line 1, 2 가 lock-step 으로 같이 실행하나 , 라인 1의 write 결과가 메모리에 반영되기 전에 라인2 의 read 가 실행될 수 있기 떄문에 이런 memory 쪽은 동기화를 시켜줘야 했다.
4) 같은 메모리 주소에 여러 스레드가 접근하면
warp 안 여러 thread 가 같은 메모리 주솔르 동시에 건드리면 , 그 순서가 정의되지 않는다.
Non atomic write : 같은 warp 의 둘 이상의 thread 가 memory location 에 대해 non-atomic write 하면 그 write 들은 serialized ( 직렬화 ) 한다.
-> 쉽게 말하면 동시에 한 주소에 막쓰면 충돌 나니까 , 하드웨어가 사실상 줄 세워서 하나씩 처리하는 것 이다.
하지만 serialized 되더라도 최종적으로 어떤 thread 값이 남는지는 불문명하다.
atomic : global memory location 에 대해 여러 thread 에서 실행되면 , 순서는 알 수없지만 결과는 정확하다.
<정리>
- warp = 32 thread
- warp마다 PC 하나
- warp 안 thread들은 같은 instruction을 같이 실행
- divergence가 나면 한 branch씩 순서대로 실행
- 현재 path에 없는 thread는 inactive(masked)
[ Volta ]
이제 Volta ( cc 7.0 2017) 부터 생기는 변화들을 자세히 알아보자.
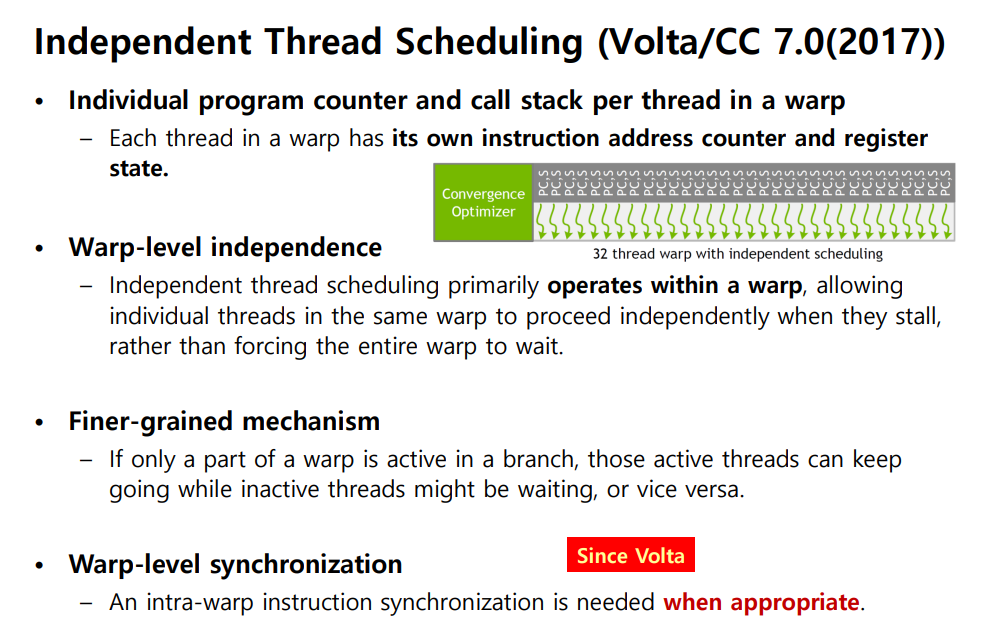
위에서도 자세히 살펴 봤듯이 Before Volta 에서는 warp 하나가 Single PC & call stack 을 공유했다. warp 전체가 하나의 instruction address counter 로 관리되었고 , lock-step 으로 실행되었다. 하지만 Volta 부터는 완전히 바뀌게 되었다.
Volta
- thread마다 개별 program counter / call stack
- warp-level independence
- finer-grained mechanism
- 필요하면 intra-warp synchronization 필요
이렇게 크게 4가지 정도가 존재한다.
1. Thread 마다 PC / register state
volta 부터는 warp 안 각 thread 가 자기만의 instruction address counter 와 register 를 가진다.
( 이전에는 warp 당 PC 1개 )
2. Warp-level independence
Independent threas scheduling 이 primarily operates within a warp 이다.
즉 , grid 전체나 block 전체가 갑자기 thread - by - thread 로 스케줄 된다는게 아니라 , 같은 warp 안에서도 개별 thread 가 stall 시 더 독립적으로 진행하능하다는 것이다. 어떤 thread 가 stall 되더라도 예전처럼 warp 전체를 묶어서 기다리게 하지 않고 , 가능한 thread 들은 더 진행할 수 있다.
이렇게되면 한 thread 가 메모리 대기나 늦어진다고 해서 , 같은 warp 의 다른 thread 까지 무조건 같이 대기할 필요가 없어진다.
** Q : 그러면 다른 warp의 부분을 돌린다는건가 ?
A : 아니다.
(With claude)
핵심부터: Warp는 여전히 스케줄링의 기본 단위
Independent Thread Scheduling이라고 해서 쓰레드가 CPU처럼 개별적으로 자유롭게 돌아다니는 게 아니야. Warp 32개 쓰레드는 여전히 같은 Processing Block의 32개 CUDA Core에 1:1로 매핑되어 있고, Warp Scheduler가 warp 단위로 issue하는 구조는 바뀌지 않았어.
Warp Scheduler
│
▼ (warp 단위로 선택)
┌─────────────────────────────┐
│ Warp 7의 32 threads │
│ → 32 CUDA Cores에 매핑 │
│ → 이번 cycle에 실행 │
└─────────────────────────────┘
그러면 뭐가 달라진 건데?
달라진 건 warp 내부에서 divergence를 처리하는 방식이야.
Before Volta: diverge하면 branch A 쓰레드 전부 → branch B 쓰레드 전부, 이렇게 완전히 순차 실행. 하나의 PC를 공유하니까 선택지가 없음.
Since Volta: 각 쓰레드가 자기 PC를 갖고 있으니까, 하드웨어가 sub-warp 단위로 "이번 cycle에는 branch A 쓰레드들 실행, 다음 cycle에는 branch B 쓰레드들 실행"을 더 유연하게 interleave 할 수 있어. 핵심은 여전히 한 warp 안에서 일어나는 일이라는 거야.
Before Volta (rigid serial):
cycle 1~4: [A; A; B; B;] ← thread 0~15만 (16~31 stall)
cycle 5~8: [X; X; Y; Y;] ← thread 16~31만 (0~15 stall)
cycle 9~: reconverge → [P; Q;]
Since Volta (flexible interleave):
cycle 1: [A] thread 0~15
cycle 2: [X] thread 16~31 ← 바로 교대 가능
cycle 3: [B] thread 0~15
cycle 4: [Y] thread 16~31
cycle 5: [P] thread 0~15 ← 먼저 도달 가능
...
"다른 warp의 쓰레드가 빈 자리에 들어오는 거냐?"
아니야. 32개 CUDA Core는 현재 실행 중인 warp에 전속되어 있어. 다른 warp의 thread가 끼어들지 않아.
다만 네가 생각하는 메커니즘이 warp-level context switching(= latency hiding)이랑 헷갈린 것 같은데, 그건 Volta 이전부터 항상 있던 기능이야:
Warp Scheduler가 가진 resident warp pool:
[Warp 0] [Warp 1] [Warp 2] ... [Warp N]
cycle 1: Warp 0 실행 → memory access로 stall
cycle 2: Warp 0 전체가 대기 → Scheduler가 Warp 3 선택해서 실행
cycle 3: Warp 3 실행
cycle 4: Warp 0의 데이터 도착 → 다시 ready 상태로
...
이건 warp 간 전환이고, Independent Thread Scheduling은 warp 내부의 얘기야. 두 개는 서로 다른 레벨의 메커니즘이지.
그래서 warp로 묶는 이유?
여전히 warp가 존재하는 이유는 하드웨어 효율 때문이야:
명령어 fetch/decode 비용 절감 — 32개 쓰레드가 (가능하면) 같은 명령어를 실행하니까, instruction fetch와 decode를 1번만 하면 32개 연산이 나가. 만약 쓰레드마다 완전히 독립적으로 스케줄링하면 fetch/decode 유닛이 32배 필요하겠지. GPU가 수천 개의 쓰레드를 돌릴 수 있는 건 이 "SIMT 묶음 실행" 덕분이야.
Convergence Optimizer의 역할 — Volta가 한 건, 엄밀히 말하면 "warp를 없앤 게 아니라, divergence 상황에서 warp 내부를 더 스마트하게 관리하는 것"이야. 쓰레드들이 같은 PC에 다시 모이면 Convergence Optimizer가 즉시 reconverge 시켜서 다시 32-wide SIMT 효율을 회복해.
내 이전 설명 정정
"stall된 쓰레드를 기다리지 않아도 됨"이라고 쓴 부분은 좀 과하게 표현했어. 더 정확하게는: divergent branch 상황에서 active thread subset이 inactive thread를 기다리며 완전히 block되지 않고, 하드웨어가 sub-warp 단위로 유연하게 교차 실행할 수 있게 됐다 정도가 맞아. 개별 쓰레드가 완전히 자유롭게 독립 실행되는 건 아니야.
3. Fine-grained mechanism
branch에서 warp의 일부만 active라면, active thread들은 계속 가고 inactive thread는 기다릴 수 있다. 또는 그 반대도 가능하다
무슨말인지 조금 더 이해를 자세히 해보기 위해서 아래그림을 보면 ..
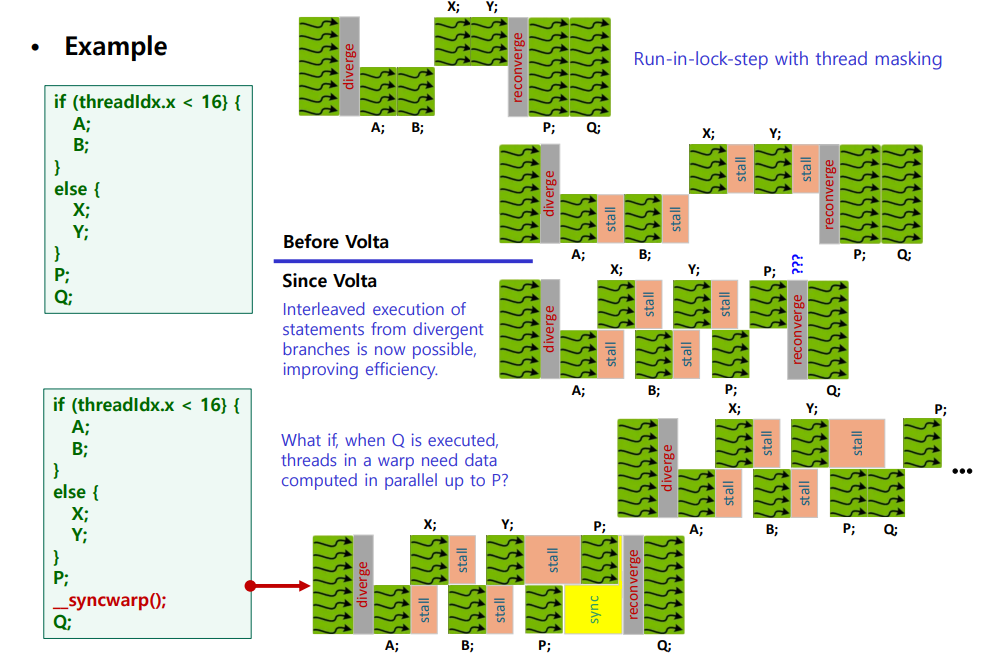
< Before Volta >
코드를 보면 warp 안 0~15 thread 는 A,B / 나머지는 x,y 로 간다.
여기서는 warp 가 lock-step 이라서 실제로 :
1. A,B path 실행될 차례
-> 해당 안되는 곳은 mask off
2. x,y path 차례
-> 마찬가지
3. reconverge
4. P/Q 공통 구간 실행
이런식으로 이루어진다.
<Since Volta >
이제 divergent branch 의 statment 들이 interleaved 될 수 있다.
그래서 어떤 lane 들은 branch path 써서 더 빨리 진행하고 어떤 lane 은 아직 다른 path 에 남아 있을 수 있다.
(그래서 슬라이드에 P ??? 써져있는 것임 )
그래서 volta 에서는 Q 가 실행되는 시점에 warp 안 thread 들이 병렬로 계산해 두어야할 p 까지 데이터가 정말 다 있는가 ?
이걸 알 수가 없다.
4. warp - levl synchronization
그래서! warp 간의 동기화가 필요한 것이다. ( 기억이 날지 모르곘는데 앞에서 코드에서 해멨던 이유가 이쪽 파트를 제대로 못들어서 그런 듯 하다 )
위 그림에서도 볼 수 있듯이 __syncwarp() 를 써야 한다.
__syncwarp()
Q 가 warp 안에 다른 thread 들의 P 단계 결과에 의존을 할 경우에 , P 뒤에서 warp-level barrier 를 넣어야 한다.
이 이야기는 뒷 챕터에서 더 자세하게 다뤄보자.
Synchronization within a Warp (Volta/CC 7.0 or Later)
바로 이야기가 진행된다. __synwarp() 가 무엇이며 __synthreads() 와는 무엇이 다를까 ?

void __syncwarp(unsigned mask = 0xffffffff);
의미 : mask 에 지정된 warp lane 들이 모두 같은 __syncwarp() call 에 도달할때 까지 기다린다.
그리고 그 thread 사이에 memory ordering 도 보장한다.
즉 2가지
- execution synchronization
- memory ordering / visibility 보장
를 보장해준다.
cf.
execution synchronization 이란 ?
: warp 안에서 내가 지정한 lane 들이 모두 이 지점까지 오기 전에는, 먼저 온 thread 도 다음으로 못간다.
크게 다른 의미는 없고 위 코드에서
P -> __synwarp() -> Q
형태에서 먼저 온 thread 는 기다리고 , 나머지 participating lane 도 "다" 도착하면 그 다음에 다같이 Q 로 간다. \
Volta 이후 깨질 수 있는 암묵적 하자를 명시적 barrier 로 다시 만들어주는 것이다.
memory ordering 보장
- barrier 이전에 warp thread들이 global/shared memory에 수행한 read/write는
- barrier 이후에 같은 warp의 participating thread들에게 visible하다고 설명한다.
이것도 어려운게 아니라 thread 들이 메모리 통해서 통신하려면 다음과 같이 ,
shared[lane] = my_value;
__syncwarp();
x = shared[other_lane];
1. 각 thread 가 먼저 자기 값을 shared / globla 메모리에 쓰고
2. __synwarp() 에서 participating lane 들이 다 도착할때 기다리고 ( 이때 memory ordering 을 보장 )
3. 이후에는 안전하게 읽을 수 있다.
( 아까도 설명했지만 , memory ordering 이 없으면 코드 자체는 수행이 끝났으나 메모리에 적는 시간차이로 인해서 race 가 발생할 수 있기 때문. )
Notes
- __syncthreads() 보다 훨씬 가볍고 빠르다 ( block 전체가 아니라 warp 32 개 내부여서 )
- mask
__activemask()
: 지금 이 순간, 이 warp에서 실행 중인 쓰레드가 누구냐 를 알려주는 조회용 intrinsic. ( 그냥 읽기만 )
반환값은 32-bit unsigned int 이다.
각 bit 가 warp 의 lane 0~31 에 대응한다 ( bit = 1 -> active )
( __activemask() + __syncwarp() 조합 패턴 )
unsigned active_threads = __activemask();
__syncwarp(active_threads);
(간단한설명)
mask는 뭔가
__syncwarp(mask)의 mask는 어떤 lane들이 이 sync에 참여하는지 나타내는 32-bit 비트마스크다.
강의자료는 __activemask()도 같이 소개하는데, 이 함수는 현재 calling warp에서 active한 thread들의 32-bit mask를 반환한다. n번째 lane이 active면 n번째 bit가 1이다. inactive lane은 0이다.
그래서 보통 이런 식으로 쓴다.
__syncwarp(active_threads);
의미는:
지금 실제로 active한 lane들만 기준으로 warp barrier를 걸자
이다. 강의자료도 이 사용 예를 그대로 보여준다.
그니까 쉽게 말해서 " 현재 active인 쓰레드끼리만 sync하겠다 " 라는 뜻이다.
왜 이게 유용하냐면, 상황에 따라 warp 32개 중 일부만 살아있는 경우가 있거든:
if (threadIdx.x < 24) {
// lane 0~23만 여기 진입
shmem[threadIdx.x] = compute_something();
// 여기서 __syncwarp() 기본값(0xFFFFFFFF)을 쓰면?
// → lane 24~31도 여기 도달하길 기다림
// → 근데 걔들은 else branch에 있어서 영원히 안 옴
// → DEADLOCK 또는 UNDEFINED BEHAVIOR!
// 올바른 방법:
unsigned active = __activemask(); // 0x00FFFFFF
__syncwarp(active); // 0~23끼리만 sync
result = shmem[threadIdx.x ^ 1]; // 안전하게 이웃 값 읽기
}
다음과 같다.
** 의문점. 그러면 어떤식으로 __activemask() 활성화를 아는거지 ?
( with claude )
-> 미리 예측하는 게 아니라, 호출하는 바로 그 순간의 하드웨어 상태를 읽는 것.
하드웨어가 관리하는 active mask
Warp Scheduler는 항상 warp 내 32개 lane 각각이 active인지 inactive인지를 하드웨어 레지스터로 추적하고 있어. 이건 프로그래머가 만드는 게 아니라 하드웨어가 실시간으로 관리하는 거야.
Warp Scheduler 내부 상태 (항상 존재):
lane: 0 1 2 3 4 5 ... 30 31
state: 1 1 1 0 0 1 ... 1 0
↑ ↑
active inactiveif문을 만나면 하드웨어가 조건 평가 결과에 따라 이 mask를 자동으로 갱신해:
if (threadIdx.x < 16) {
// 하드웨어가 자동으로:
// lane 0~15 → active
// lane 16~31 → inactive (다른 branch path)
// 이 시점에서 __activemask() 호출하면
// 하드웨어가 "지금 내 active mask 읽어줘" → 0x0000FFFF 반환
}
```
## `__activemask()`는 그냥 스냅샷
`__activemask()`가 하는 일은 딱 하나야: **"하드웨어야, 지금 이 warp의 active mask 값 좀 알려줘"** → 그 순간의 값을 32-bit int로 반환. 끝.
```
__activemask()의 동작:
1. 하드웨어 active mask 레지스터 읽기
2. 그 값을 unsigned int로 반환
3. 끝. 다른 거 없음.그래서 같은 코드 줄이라도 호출 시점에 따라 값이 다를 수 있다는 거야. 하드웨어 상태는 매 순간 바뀌니까.
비유하자면
카페에서 "지금 이 방에 누가 있어?" 하고 사진을 찍는 거랑 같아. 사진 찍는 순간 방에 있는 사람만 찍히지, 1분 후에 들어올 사람은 안 찍혀. __activemask()도 마찬가지로, 호출하는 그 clock cycle에 active인 쓰레드만 반환하는 거야. 곧 도착할 쓰레드는 모르고, 미리 예측하지도 않아.
q.
으응.. 엥 ? 그러면 알수가 없는거 아니야 ? 그니까 하드웨어가 activemask() 호출을 할때
만약에 1 , 2 번만 active 였는데 나중에 3번도 사실은 active 일수도 있잖아 ( thread 연산 차이가 나면 ? )
맞아, 정확히 그거야. 그게 바로 __activemask()의 한계인 거야.
네가 말한 상황 그대로
코드: 분기 없음, 32개 쓰레드 전부 같은 path
하드웨어 실행 상태 (어떤 시점):
lane 0: ██████ __activemask() 호출 시점 ← 여기
lane 1: ██████ __activemask() 호출 시점 ← 여기
lane 2: █████░ ← 아직 이전 연산 처리 중
lane 3: ████░░ ← 더 느림
__activemask() 반환값: 0x...0011 (lane 0,1만)
실제로는 lane 2,3도 곧 도착할 건데,
이 시점에선 "아직 안 왔으니까 inactive"로 찍힘
네 말이 100% 맞아. 그래서 __activemask()는 "지금 누가 있냐"는 알려주지만, "누가 있어야 하냐"는 모르는 거야.
그럼 __activemask()는 언제 믿을 수 있어?
확실하게 믿을 수 있는 경우는 딱 하나: branch 안에서. if문으로 갈라진 상황에서는 하드웨어가 조건 평가를 통해 "이 branch에 속하는 쓰레드"를 정확히 결정했으니까:
if (threadIdx.x < 16) {
// 여기 들어온 건 확실히 lane 0~15
// 16~31은 else에 있으니 절대 안 옴
unsigned mask = __activemask(); // 0x0000FFFF ← 믿을 수 있음
__syncwarp(mask); // 안전
}
이건 "연산 속도 차이로 늦게 도착"이 아니라 **"조건에 의해 구조적으로 여기 안 오는 것"**이니까, active mask가 정확해.
믿을 수 없는 경우: 분기 없는 코드
// 분기 없음 — 32개 전부 같은 path
shmem[threadIdx.x] = val;
unsigned mask = __activemask(); // ← 0xFFFFFFFF가 아닐 수 있음!
__syncwarp(mask); // ← 일부 쓰레드를 빠뜨릴 수 있음
result = shmem[threadIdx.x + 1]; // ← 위험!
이 경우는 그냥 mask를 직접 써:
shmem[threadIdx.x] = val;
__syncwarp(0xFFFFFFFF); // "32개 전부 기다려" — 확실
result = shmem[threadIdx.x + 1]; // 안전
정리
__activemask() 신뢰도:
branch 내부에서 사용 → 신뢰 가능 (구조적으로 active set 확정)
분기 없는 코드에서 사용 → 신뢰 불가 (Independent Thread Scheduling 때문)
결론:
"누가 참여해야 하는지" 프로그래머가 아는 상황이면
→ mask를 직접 지정하는 게 더 안전
네가 짚은 포인트가 정확히 __activemask()의 근본적 한계야.
뭐 근데 사실 여기까지는 학/석사 연계 과목여도 그정도로 깊게 다루는 거 같지는 않다. (아마도?)
( mask 규칙: Each calling thread must have its own bit set in the mask and all non-exited threads named in mask must execute a corresponding __syncwarp() with the same mask, or the result is undefined. )
무슨말이냐면
1. 자기 bit 가 mask 에 켜져 있어야함 ( 당연하게도 )
2. mask에 지정된 모든 non-exited 쓰레드가 동일한 mask로 호출해야 함
다만 __activemask() 가 위험성이 있다.
앞서서 나도 읽다보니까 의문점이 든 것들도 있었고 ( 위에 참고 )
// divergence 없는 코드인데도:
unsigned mask = __activemask();
// Volta 이후에는 일부 쓰레드가 다른 속도로 진행 중일 수 있어서
// mask가 반드시 0xFFFFFFFF라는 보장이 없음!
```
그래서 NVIDIA 공식 가이드에서는 `__activemask()`를 sync 목적으로 쓰는 걸 신중하게 하라고 해. 확실한 동기화가 필요하면 **프로그래머가 mask를 직접 계산**해서 넘기는 게 더 안전한 경우도 있어.
## 정리
```
__activemask()
├── 역할: 현재 active 쓰레드 조회 (read-only, 상태 변경 없음)
├── 반환: 32-bit mask (bit n = 1이면 lane n이 active)
├── 용도: __syncwarp()에 넘길 mask 생성
├── 장점: branch 안에서 "나랑 같이 있는 애들끼리만 sync" 가능
└── 주의: Volta 이후 동일 코드 위치에서도 시점에 따라 값이 달라질 수 있음
→ 확실한 sync가 필요하면 mask를 직접 계산하는 것도 고려
라고 한다고 한다. ( 이건 그냥 호기심에 찾아본 것. )
다시 이전에 본 예제로 돌아오면

이제는 훨씬 오른쪽 코드의 의미가 분명해졌다.
id<64 까지는 여러 warp 가 관여하기 때문에 synthreads() 로 관리를 한 것이고 ( block-wise sync )
id <32 부터는 warp 0 하나만 관여 하기 때문에 block 전체를 기다릴 필요 없이 warp 내부만 맞추면 된다.
잘못쓰는 예시들
__syncwarp()를 쓸 때 지켜야 하는 규칙
강의자료와 Programming Guide 둘 다 아주 중요한 제약을 말한다.
강의자료 요약
- 각 calling thread는 자기 own bit가 mask에 set되어 있어야 한다
- mask에 포함된 모든 non-exited thread는 **같은 mask 값으로 대응되는 __syncwarp()**를 실행해야 한다
- 아니면 결과는 undefined다.
Programming Guide가 더 자세히 말하는 조건
- calling thread가 mask에 포함되어 있어야 함
- mask에 포함된 non-exited thread는 결국 같은 program point에서 같은 intrinsic을 호출해야 함
- conditional code 안이라면, mask에 포함된 thread들에 대해 조건 평가가 일관되어야 함
- disjoint한 mask라면 서로 다른 warp sync intrinsics를 동시에 써도 가능하다.
즉 아주 쉽게 말하면:
같이 기다리기로 한 lane들은, 진짜 다 같은 약속 장소로 와야 한다.
누군가 mask에 이름이 올라가 있는데 안 오면,
barrier semantics가 깨져서 undefined behavior가 난다.
11) 잘못 쓰는 예를 감으로 이해해보자
예를 들어 이런 상황은 위험하다.
if (lane < 16) {
__syncwarp(mask);
}
왜 위험하냐면:
- mask는 32 lane 전부를 포함하는데
- 실제로 호출하는 건 0~15 lane뿐이기 때문이다
그러면 16~31 lane은 barrier에 안 오는데, mask에는 포함되어 있으니 조건이 안 맞는다.
이런 류는 Programming Guide 기준으로 invalid/undefined다.
반대로 이런 구조는 더 자연스럽다.
__syncwarp(mask);
혹은 divergence된 두 집단이 서로 disjoint mask를 써서 각각 sync하는 형태다.
Extensions to the Classical CUDA Execution Model: Grid Synchronization Using Cooperative Groups (Volta/CC 7.0)
강의에서 너무 심도있게 다루지는 않는다. ( 아마 분량때문에 ) 하지만 이것저것 좀 더 사족을 붙여서 정리해볼까 한다.

Classical CUDA 모델에서는 동기화에 두 가지 한계가 있었어:
Block 내부만 동기화 가능: __syncthreads()는 하나의 thread block 안의 thread들끼리만 barrier 동기화를 걸 수 있었다.. 서로 다른 block 간에는 동기화 수단이 전혀 없었다.
Grid 전체 동기화 = kernel 종료: Grid 내 모든 thread block이 특정 지점까지 실행됐는지 보장하려면, kernel을 아예 끝내고 새 kernel을 launch하는 수밖에 없었다. 이건 커널 launch overhead가 크기 때문에 비효율적이다.
Cooperative Groups 를 쓰면 조건부로 grid 전체 block 까지 한번에 동기화가 가능해진다.
Cooperative Groups 이란 ?
Cooperative Groups는 CUDA C++에서
“협력하는 thread들의 그룹”을 명시적으로 다루는 기능이다.
이걸 쓰면 커널을 끝내지 않고도 특정 범위의 thread들을 동기화할 수 있다.
슬라이드에서는 총 그룹 단위를 이렇게 본다.
- tiled partition: block 내부의 더 작은 그룹
- thread block group: 현재 block 전체
- grid group: grid 전체 block들
- cluster group: Hopper에서의 cluster 단위
여기서 Grid synchornization 파트만 조금 더 자세히 본다.

grid-levl synchoronziation
CG 를 쓰면 grid 전체 block 들이 커널 안에서 만나서 barrier 를 걸 수 있다.
별거 없고 앞에서 이야기 했던 barrier 의 기준이 thread block 간으로 바뀌었다고 보면 된다.
** 중요한 조건이 있다.
co-residency contraint 인데
"grid sync 를 하려면 해당 grid 의 "모든" block 이 동시에 GPU 에 올라와 있어야 한다 " ( 중요 )
그니까 GPU 에 올라와 있어야 한다는 말은 즉 , SM 에 있어야 한다는 말인데. 이게 매우 어렵다.
예를들어서..
- GPU가 동시에 올릴 수 있는 block 수: 20개
- 네가 launch한 block 수: 100개
그러면 처음엔 20개만 resident 상태다.
그런데 이 20개가 먼저 grid.sync()에 도착하면, 나머지 80개도 barrier에 와야 풀린다.
문제는:
- 먼저 도착한 20개가 SM 자리를 차지하고 기다림
- 아직 실행도 못 한 80개는 올라올 자리가 없음
- 결국 서로 기다리기만 하면서 deadlock
그래서 block 간 동기화를 위해서는 반드시 모든 block 이 SM 에 올라와 있어야 한다.
그러면 과연 큰 데이터셋에서는 어떻게 잘 돌려볼 만한 방법이 없을까 ?
Grid-stride loop
큰 데이터셋을 -> 적은 수의 block 으로 나눈 다음에 처리한다.
그러니까 원래 큰 데이터면 보통 block 수를 엄청 많이 launch 하고 싶어하는데 , grid sync 쓰려면 block 이 다 올라와 있어야 한다. 그래서
block 수를 launch 할 수 있는 만큼 작게 유지하고
대신 각 thread 가 여러 원소를 반복 처리한다. ( 작게 잘라서 )
Extensions to the Classical CUDA Execution Model: Thread Block Cluster (Hopper/CC 9.0)
방금 위에서 말했던 예외 말고도 thread block 을 동기화 할 수 있는 방법이 한개 더있다.
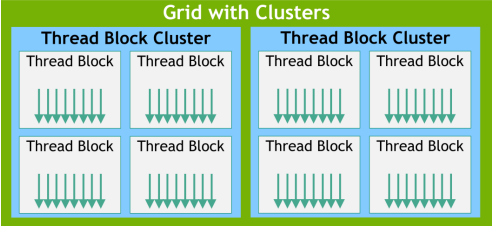
cc 9.0 부터 Thread Block Cluster 라는 중간 계층 ( optional hierarchy ) 가 추가 되었다. 원래
grid
└─ thread block
└─ thread
이런 계층이였다면
grid
└─ thread block cluster <- optional
└─ thread block
└─ thread
이런식으로 하나 더생겼다고 한다.
예외는 그냥 그정도가 있다 ! 정도로 알고 넘어가도 당장은 큰 지장은 없어보이긴 하나
궁금하면 더 찾아보는 것을 추천한다.

이제 진짜 진짜 마지막으로 마무리하고 이번 챕터는 끝내보도록 하겠다. 사실 크게 어려운 내용은 없으면서도
( 오히려 시프같은 과목보다 양이 훨씬 적은것 같다 ) 원래 개념과 좀 다른 부분이 GPU 에 있어서 gpu 방식으로 생각하는게 약간 걸렸지만 , GPGPU 잘 따라 오다 보니까 확실히 GPU 에 대해서 이해도가 높아진거 같기는하다.
그래서 뭐 MAMBA 나 FLASH ATTENTION 같은 하드웨어 쪽과 붙어있는 논문을 읽을때도 확실히 이해가 많이 높아져서 좋다.
Important Notes


* 내용이 쉬워서 번역만 해둔다.
Q1: Warp 내 32개 thread가 항상 같은 instruction을 실행하는가?
Before Volta (CC < 7.0): Yes
Warp 전체가 PC 하나를 공유하고 lock-step으로 진행했어. Branch divergence가 발생하면 한쪽을 먼저 실행하고, 다른 쪽은 thread masking으로 비활성화시켜서 순차 처리했지.
if (threadIdx.x < 16) { A; B; }
else { X; Y; }
P; Q;
[Pre-Volta 실행 타임라인]
time ──────────────────────►
thread 0~15: ██ A ██ B ██ stall ██ P ██ Q ██
thread 16~31: ██ stall ██ X ██ Y ██ P ██ Q ██
↑ ↑
diverge reconverge
→ 한 시점에 active한 쪽만 실행, 나머지는 놀고 있음
→ 대신 lock-step이니까 reconverge 후 warp 내 동기화가 "암묵적으로" 보장됨
Since Volta (CC 7.0+): No
각 thread가 개별 PC + 개별 call stack을 갖게 됨. Divergent branch의 양쪽이 interleave되어 실행될 수 있어서 효율이 올라갔어.
[Since Volta 실행 타임라인]
time ──────────────────────►
thread 0~15: ██ A ██ B ██ P ██ ??? ██ Q ██
thread 16~31: ██ X ██ Y ██ P ██ ??? ██ Q ██
↑
여기서 다른 thread의 P 결과가 보장 안 됨!
효율은 좋아졌지만, 대가로 암묵적 동기화 보장이 깨졌어. Q에서 다른 thread가 P까지 계산한 결과를 읽어야 한다면, 반드시 명시적 동기화를 넣어야 해:
P;
__syncwarp(); // ← 이거 없으면 다른 thread의 P 결과를 못 볼 수 있음
Q;
__syncwarp() 외에 __shfl_up_sync() 같은 _sync suffix intrinsic들도 암묵적으로 warp 동기화를 포함하고 있어.
Q2: Grid 내 thread block들끼리 동기화할 수 있는가?
Default: No
각 thread block은 논리적으로 독립 실행돼. 어떤 block이 어떤 SM에 언제 배정될지 알 수 없고, block 간 실행 순서도 보장 안 돼. 전체 block이 공통 지점에 도달했음을 보장하는 유일한 방법은 kernel을 종료하는 것뿐이야.
Exception 1: Cooperative Groups (CC 7.0+)
grid.sync()로 kernel 종료 없이 grid 전체를 동기화할 수 있어. 단, 모든 block이 동시에 SM에 상주(co-residency) 해야 하기 때문에, block 수가 GPU가 동시에 수용 가능한 수를 넘으면 사용 불가.
Exception 2: Thread Block Cluster (CC 9.0+)
cluster.sync()로 같은 GPC에 co-schedule된 cluster 내 block들(최대 8개) 만 동기화. Grid 전체가 아닌 부분 동기화라 co-residency 제약이 훨씬 가벼움. 추가로 cluster 내 block들은 서로의 shared memory에 접근 가능 (Distributed Shared Memory).
동기화 계층 요약
범위 수단 조건 도입 시점
─────────────────────────────────────────────────────────────────
Warp 내 __syncwarp() Volta부터 명시적 필요 CC 7.0
Block 내 __syncthreads() 항상 가능 초기부터
Cluster 내 cluster.sync() 같은 GPC co-schedule CC 9.0
Grid 전체 grid.sync() 전체 block co-residency CC 7.0
Grid 간 kernel 종료 후 재launch 항상 가능 초기부터
핵심 메시지: Volta 이후로는 **"암묵적 동기화에 의존하지 마라"**가 원칙이고, 동기화 가능한 범위가 warp → block → cluster → grid로 점점 확장되어 왔다는 흐름이야.
QnA
Q. warp < thread block 인데 thread block 단위로 shared memory 쓸 수 있으니까 한 블럭안에 들어간 SM 끼리는 warp 끼리도 통신가능한거지 ?
A.
거의 맞는데 용어 관계를 살짝 정리해줄게.
Thread Block → SM 매핑은 N:1이 아니라 반대야. 하나의 thread block은 하나의 SM에 통째로 할당돼. 쪼개져서 여러 SM에 분산되는 일은 없어. 반대로 하나의 SM은 리소스(레지스터, shared memory)가 허용하는 한 여러 block을 동시에 들고 있을 수 있고.
그래서 구조를 정리하면:
SM (하드웨어)
├── Block A (shared memory A)
│ ├── Warp 0 (thread 0~31)
│ ├── Warp 1 (thread 32~63)
│ └── ...
├── Block B (shared memory B) ← 같은 SM이지만 별도 shared memory
│ ├── Warp 0
│ └── ...
핵심은 이거야:
같은 block 안의 warp끼리 — shared memory로 통신 가능. __syncthreads()로 동기화도 됨. 네가 말한 게 이 경우라면 맞아.
같은 SM에 올라간 다른 block의 warp끼리 — shared memory가 block 단위로 격리되어 있어서 직접 통신 불가. 같은 SM 위에 물리적으로 같이 있어도 논리적으로는 완전히 독립이야.
그래서 "SM끼리 통신"이라는 표현보다는, block 내부에서 warp 간 shared memory 공유가 가능하다고 이해하는 게 정확해. SM은 그냥 block을 실행해주는 하드웨어 유닛이고, 프로그래머가 신경 쓰는 추상화 단위는 block과 grid야.
한 줄 요약: shared memory의 scope = thread block. warp가 아니라 block 기준으로 공유/격리가 결정돼.
Q. 어떤 계산 같은 문제가 나올 것같은데 ( 그니까 뭐 grid 갯수 부터 해서 warp 어쩌구 저쩌구.. ) 이건 어떻게 할까
A. 족보가 나온다고 하니 그때 생각해보자. 개념을 우선으로 하고 시험기간에만 계산에 친숙해지는걸로
Q. 데이터가 같은데 명령이 다르면 ? WARP 로 못묶이나 ?
A.
결론부터 말하면:
warp는 무조건 32-thread 묶음으로 만들어진다.
문제는 “못 묶이는가”가 아니라,
같은 warp 안 thread들이 서로 다른 실행 경로를 가면 divergence가 생긴다는 것이다.
즉 warp 생성은 block을 32개씩 자르는 기계적인 과정이다.
명령어가 같을지 다를지는 실행 도중 분기(if/else) 에서 문제가 된다.
Volta 이전 classical model에서는 warp가 한 번에 한 경로씩 실행하면서 다른 thread를 mask off했다. 강의자료도 warp 내 branch divergence 시 각 branch path를 따로 실행한다고 설명한다.
즉 네 질문에 대한 정확한 답은:
- “명령어가 다르면 warp로 못 묶이나?” → 아니오, 여전히 warp다
- 대신 → 효율이 나빠질 수 있다(branch divergence)