Quo Vaids, Action Recognition? A New Model and the Kinetics Dataset (2018)
요약
- Video action recognition 의 새로운 데이터 셋인 kientics dataset + 새로운 모델 발표
- 이전 논문(3d conv , two stream conv ) 를 모두 포함 하고 있기 때문에 이해하기 편할 뿐만 아니라 정리하기 용이하다.
Abstract
- 기존의 video 데이터셋(UCF-101 and HMDB-51 ) 은 데이터 부족으로 인해서 좋은 아키텍쳐 인지 파악하기 힘듬
- 새로운 데이터셋 (Kinetics Dataset) 을 본 논문에서 새롭게 제시함
- 현재 아키텍쳐가 작동 하는 방법들 을 제시하고, kinetics dataset 으로 학습한 후 fine-tuning 을 통해서 작업 수행시 얼마나 성능이 향상 되었는지 제시함
- 2d conv inflated 를 기반으로 하는 새로운 모델 (new Two-stream Inflated 3D ConvNet (I3D))을 제시함
1. Introduction
- ImageNet challenge 에서 발견한 사실 (많은 양의 카테고리 이미지들을 deep architectures 에 학습시키는 것) 은 다른 도메인으로 확장하는데 많은 도움을 줄 수 있었다.
당시에 video domain 에서 large dataset 이 있다면 성능을 향상 시킬 수 있지 않을까 하는 open question 이 존재
이 질문에 답하고자 본 논문에서는 kinetics human action video dataset 을 만듬
- HMDB-51 & UCF-101 데이터셋을 합친 것 보다 큼
- 400 개의 클래스와 각 클래스에 400개가 넘는 데이터를 Youtube 에서 가지고 옴
- 기존 아키텍쳐들을 kinectics 로 pre-train 하고 HMDB-51 & UCF-101 로 fine-tuning 하면
정도의 차이는 존재하지만 모든 아키텍쳐에서 성능이 향상
- 새로운 모델도 제시 “Two-Stream Inflated 3D ConvNet (I3D) “
기본적으로 당시에 최신모델 (inception v1)을 기본 아키텍쳐로 가지고 있지만 , filter 를 inflates 하고 kernels 를 3d 로 pooling 하는 모델을 제시
2. Action Classification Architectures
- 앞에서도 이야기 했지만 image 에 대한 architecture는 빠르게 변화한 반면 video 에서는 그렇지 못함
이전까지 비디오 모델들을 정리하자면 아래와 같다.

a. 2D ConvNet & LSTM
b. two-stream networks (리뷰)
d. 3D ConvNet (C3D) (리뷰)
d. 3D-Fused Two-stream
e. Two-stream 3D-ConvNet (I3D) ( 본 논문에서 새롭게 제시)
A) ConvNet + LSTM

image classification networks 에서 좋은 성능을 낸 모델들을 재사용해서 video에서도 사용하고자 함.
Feature extraction
- 비디오에서 추출한 독립적인 frame 에서 feature 들을 얻음 —>but, issue of entirely ignore temproal stucture
Add LSTM
- 위에서 언급한 문제를 해결하기 위해 자연어 처리에서 사용했던 Recurrent layer (LSTM ..) 을 이용해서 temporal 한 정보를 보존하고자 함.
- 각 프레임에서 추출한 feautre 들을 LSTM 에 넣어서 결과값 도출
b) 3D-ConvNet

- video 를 위한 convoltion networks with spatio-temporal filter (3d Conv)
- kernel 자체가 w 와 h(spatial) 로만 움직이는 것이 아니라 depth(temporal) 라는 방향을 추가해 3개의 축을 이동해서 계산하는 방식
- 단, 2D 에 비해서 너무많은 parameter 를 가지고 있는 단점이 있기 때문에 학습시키는데 어려움이 있음.
- 또 kernel 자체가 다르기 때문에 ImageNet pre-training 을 이용하지 못하고 scartch 에서 부터 학습시켜야 하는 단점이 존재
< C3D model >

위의 사진과 다른 본 논문에서 제시한 모델에는 두가지 차이점이 있는데
1. fc layer 뒤에 batch normalization 사용
2. 기존 모델에서 첫번째 pooling layer stride = 1 이라면, 본 논문의 모델은처음부터 stride = 2
--> 메모리 사용량을 줄이고 더 큰 batch 를 사용 할 수 있도록 함
C3D 에 대한 더 자세한 설명은 https://ksh0416.tistory.com/m/79 에서 확인할 수 있다.
c) Two-Stream

- a( add LSTM ) 방식은 image 를 convnet 에 넣고나서 LSTM 에 다시 넣기 때문에 low-level motion 을 파악하기 어려울 뿐만 아니라 학습시키는 비용 역시 높다.
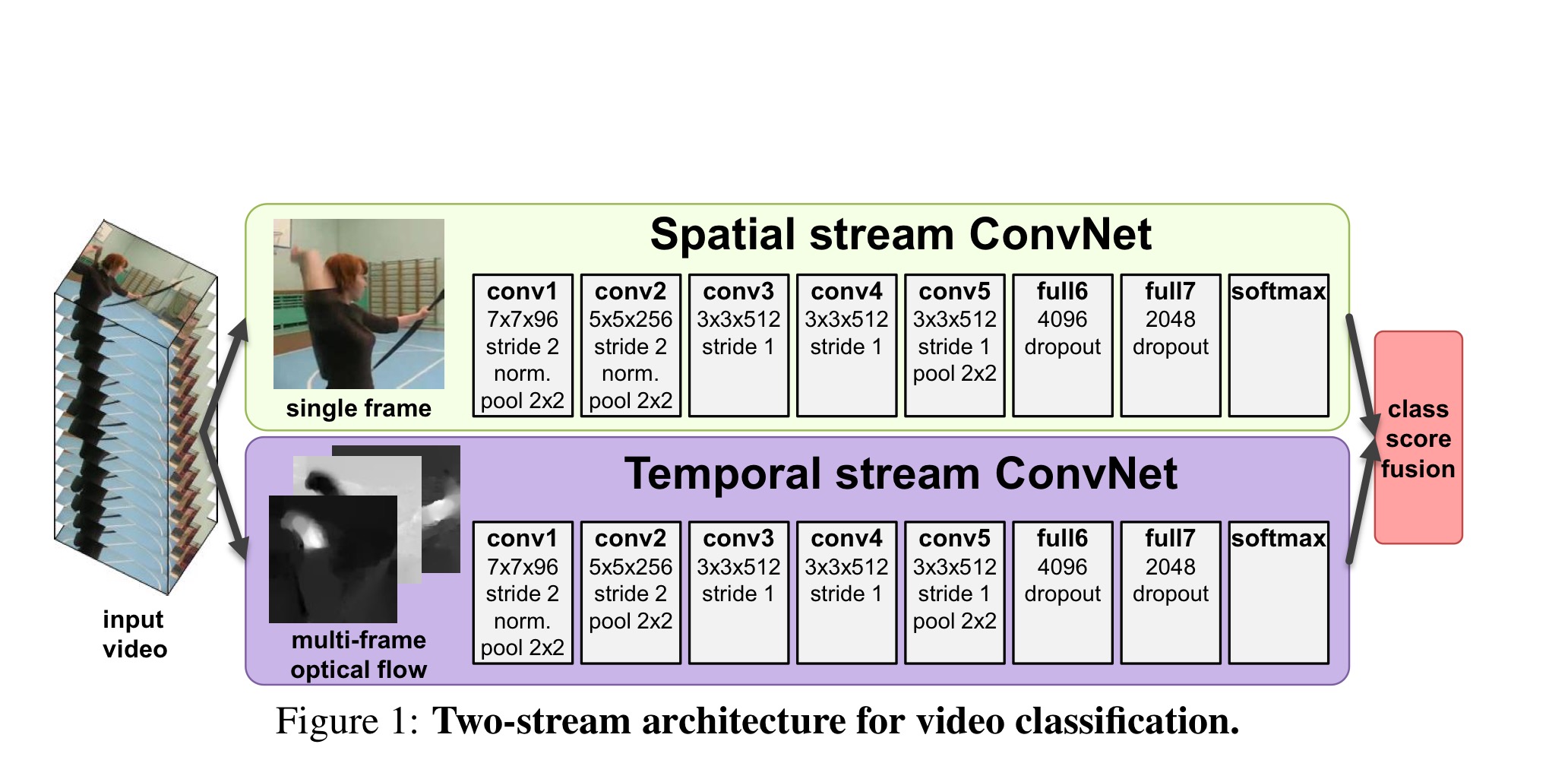
Two-Stream network
- spatial : 2d image action recognition (RGB frame / inception v1)
- temporal : opitcal flow ( frame 사이의 변화를 백터로 나타낸 것/ 10 frame stacking)
- 이 전까지는 optical flow를 계산하는게 연산량이 너무 많기 때문에 end-to-end 방식으로는 계산이 힘들고
다른 방식을 통해 구한 optical flow 를 사용해야 된다고 생각했었다.
- temporal 한 정보를 optical flow 를 통해서 구하게 된다.
- 둘 결과값의 평균을 통해서 결과값 도출
- 연산량도 매우 적고 결과 역시 뛰어났다.
two-stream network 에 대해서 더 자세히 알고 싶으면 https://ksh0416.tistory.com/77 를 참고하자
d) 3D-Fused Two-Stream


- 앞선 c) Two-Stream 모델에서 3d conv 를 한번 더 사용한 모델입니다.
- spatial stream 과 temporal stream 의 loss fusion의 계산을 3d conv 에게 찾게 함으로써 적절한 joint loss 값을 구하도록 하기 위해 위와같은 방식으로 모델을 구성하게 되었습니다.
- 계산이 매우 복잡하다.. ~
e) Two-Stream 3D-ConvNet

Inflating 2D ConvNet into 3D
- 3d conv 사용 ( but, 앞에서 정의한 3d conv 와는 다름 )
- 2D conv 구조를 그대로 사용 ( inception v1 ) —> imageNet으로 pre-train 한 정보들을 사용하도록 해 성능을 높이고자 함
- image classification 에서 좋은 성능을 내는 2D conv 의 Filters & pooling kernel 들을 inflating 함으로써 3d conv 로 이용
- Conv 를 temporal 한 축으로 확장시킴 ( N x N filter —> N x N x N )
Boostrapping 3D filters from 2D Filters
- Filter 는 time 축으로 n 번 복제 한 뒤 —> 1/n 로 rescalling
Pacing receptive field growth in space, time and network depth
- Image model 들이 spatial dimension ( weight , height ) 와 temporal 축을 똑같이 처리하는 것은 자연스럽지 않음 ( spatial - pixel 단위 / temporal - 프레임 단위 )
- 그래서 inception-v1 model 첫번째와 두뻔쨰 pooling layer 는 NxNxN 이 아닌 1x3x3 으로 구성되어 있고 마지막 역시 2x7x7 로 이루어져 있습니다.
( 경험적인 실험을 통해서 알아냈을 것 같습니다. )

보시면 inception v1 을 이용한 모델로 nxnxn pooling layer 과 1x3x3, 2x2x7 layer 가 혼용되어 사용되고 있는 걸 확인 할 수 있습니다.
* 추가로 찾아보니 본 논문의 모델을 활용해서 skeleton 관련되어 있는 연구들이 있었던 것 같습니다.
3. The Kinetics Human Action Video Dataset
Kinectics dataset
- Person actions
- 400 human action classes , with 400 or more clips for each class
- 이후로도 계속 데이터 추가
4. Experimental Comparison of Architectures

Table 2
- rgb / flow / rgb + flow 세 경우 모두 본 논문의 모델의 성능이 제일 좋다
- rgb + optical flow 를 쓴 경우가 모두 성능이 제일 좋았다.
Table 3
- imagenet 으로 pre-train 시키고 kinetics 사용하는게 더 성능이 좋다.
- 특히 RGB 에서 더 성능이 향상되었는데, 이는 예측가능한 범위인게 RGB 는 2d image 를 사용한 것과 다름 없기 때문에 2d image data 가 추가 되었으므로 , 성능 향상폭이 큰게 자연스럽다.