
(A Survey on Multimodal Large Language Models)
https://arxiv.org/abs/2306.13549
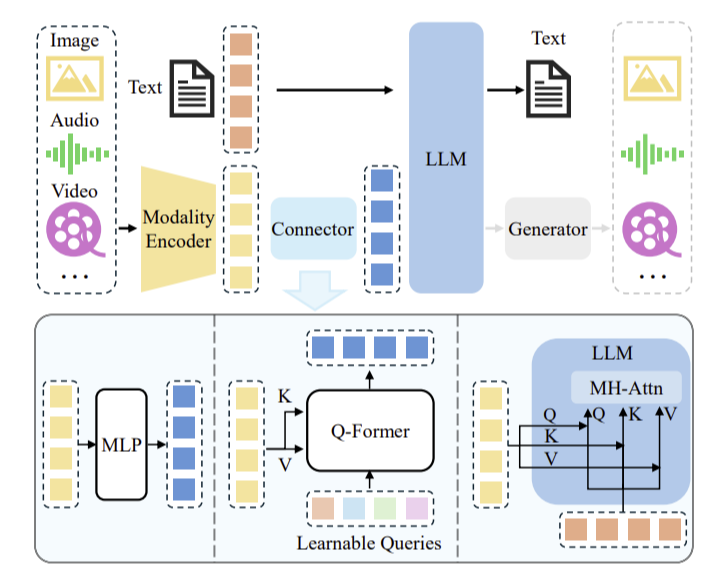
Encoder 들의 feature 들을 실제 LLM 에서 사용가능한 토큰으로 만드는게 요즘의 핵심이다. 그렇게 된다면, llm 의 능력을 활용해서 text 혹은 generator 를 붙여서 img,audio ... 을 만들 수 있다.

modalities 에 따라서 이런 방식으로 처리해준다.
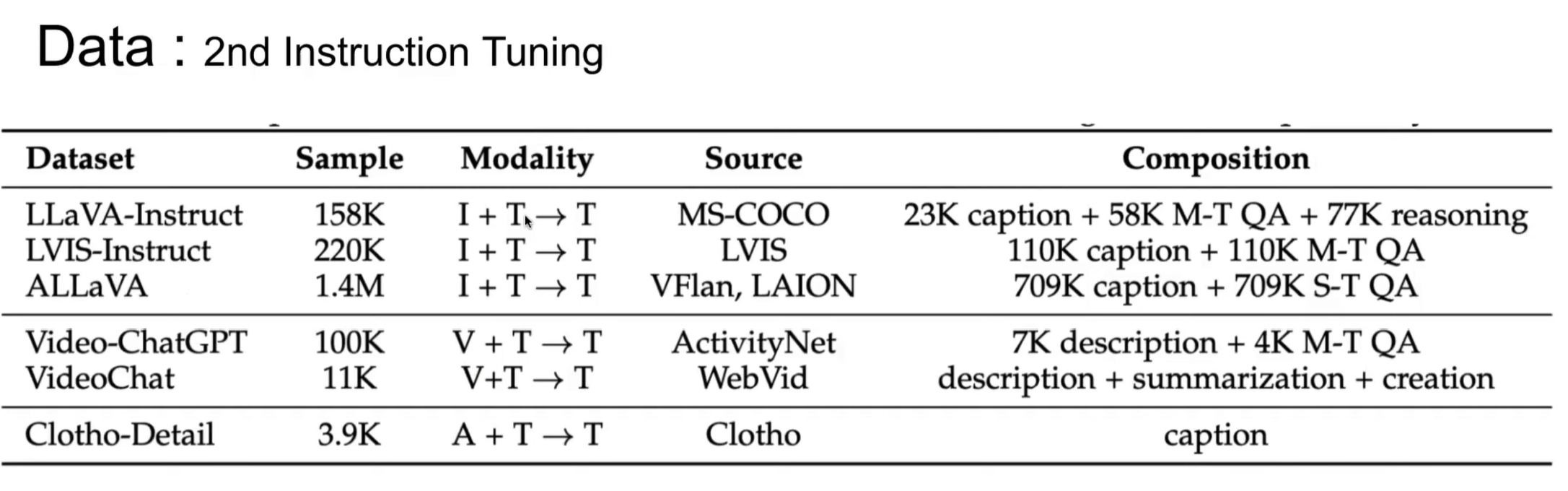
( Data set )

1차로 pre-training 할때는 보통 Q-former 을 학습시킨다. ( LLM 에 들어가는 OUTPUT 들이 이해를 할 수 있게끔 )
이후에 모델에는 어떤 것들이 있는가?
NExT-GPT , ANYGPT , ETC..
!!! +) Dataset
cauldron 이라는 dataset 이 공개 되었다. https://huggingface.co/datasets/HuggingFaceM4/the_cauldron
모든 데이터들을 하나의 레포에 가지고 있는 모델이다. 개발할때 매우 유용할듯.
1. tokenizer & Embedding & Alignment
Alignment
멀티모달에서 "alignment"는 서로 다른 모달리티(예: 이미지, 텍스트, 오디오 등) 간의 일관성 및 상관관계를 학습하는 것을 의미합니다. 구체적으로는, 동일한 의미나 내용을 가지는 서로 다른 모달리티의 표현이 서로 잘 매칭되고 연결되는 것을 목표로 합니다.
멀티모달 정렬(alignment) 방법
다양한 방법들이 멀티모달 정렬에 사용됩니다. 몇 가지 주요 방법들을 소개합니다:
1. 공동 임베딩 공간(Joint Embedding Space)
대표 모델: CLIP (Contrastive Language-Image Pre-training)
이미지와 텍스트와 같은 다른 모달리티의 데이터를 동일한 임베딩 공간으로 변환하여, 의미적으로 유사한 데이터가 서로 가까운 거리에 위치하도록 합니다.
2. 어텐션 메커니즘 (Attention Mechanism)
대표 모델: UNITER (Universal Image-Text Representation), ViLBERT (Vision-and-Language BERT), LXMERT (Learning Cross-Modality Encoder Representations from Transformers)
어텐션 메커니즘은 한 모달리티의 특정 부분이 다른 모달리티의 특정 부분과 어떻게 연관되는지를 학습합니다. 예를 들어, 텍스트의 단어가 이미지의 특정 부분과 어떻게 연관되는지를 학습할 수 있습니다.
3. 대조 학습 (Contrastive Learning)
- 대표 모델: CLIP, ALIGN (A Large-scale ImaGe and Noisy-text embedding)
- 설명: 이미지와 텍스트 임베딩이 의미적으로 유사할수록 임베딩 공간에서 가까운 거리에 위치하도록, 반대로 잘못된 설명과는 먼 거리에 위치하도록 학습합니다. 대규모의 이미지-텍스트 쌍을 사용하여 학습합니다.
4. 비지도 학습 (Unsupervised Learning)
- 대표 모델: 일부 최신 연구 모델들
- 설명: 라벨 없이 데이터를 정렬하는 방법으로, 주로 대규모의 비라벨 데이터셋에서 모달리티 간의 관계를 학습하는 데 사용됩니다.
5. 멀티모달 트랜스포머 (Multimodal Transformers)
- 대표 모델: VATT (Vision-and-Audio Transformer), MBT (Multimodal Bottleneck Transformer)
- 설명: 트랜스포머 아키텍처를 사용하여 여러 모달리티의 데이터를 처리하고 통합하는 모델들입니다. 이미지, 텍스트, 오디오 등 다양한 입력을 동시에 처리할 수 있습니다.
6. Pre-trained Vision and Language Models
- 대표 모델: VisualBERT, VL-BERT, ALBEF (Align Before Fuse)
- 설명: 사전 학습된 비전 및 언어 모델로, 이미지와 텍스트 간의 정렬을 위해 어텐션 메커니즘과 대규모의 데이터셋을 사용합니다.
* 특히 CLIP과 UNITER는 멀티모달 학습에서 매우 대표적이고 널리 사용되는 모델들
2. LLM - Model
Multimodal Transformer Training
( EX ) ViLBERT
- Masked Mutli-modal Learning : Masking된 이미지 일부 및 텍스트 일부 맞추기
- Multi-modal Aligment Prediction : 이미지와 텍스트 쌍이 서로 대응하는지 맞추기

+) Challenges
Fusion , Alignment , Transferability , Efficiency , Robustness , Universalness , interpretability
'ai' 카테고리의 다른 글
| [Vision Transformer] implement(구현) + ViT 개선방안 논문 정리 (0) | 2024.10.02 |
|---|---|
| Transformer 구현 (0) | 2024.08.11 |
| [논문]Chain-of-Thought Prompt Distillation for Multimodal Named Entity Recognition and Multimodal Relation Extraction (0) | 2024.05.04 |