
<Transformer 구현>
들어가기 앞서.. 사지방에서 만들어서 좀 엉성하다
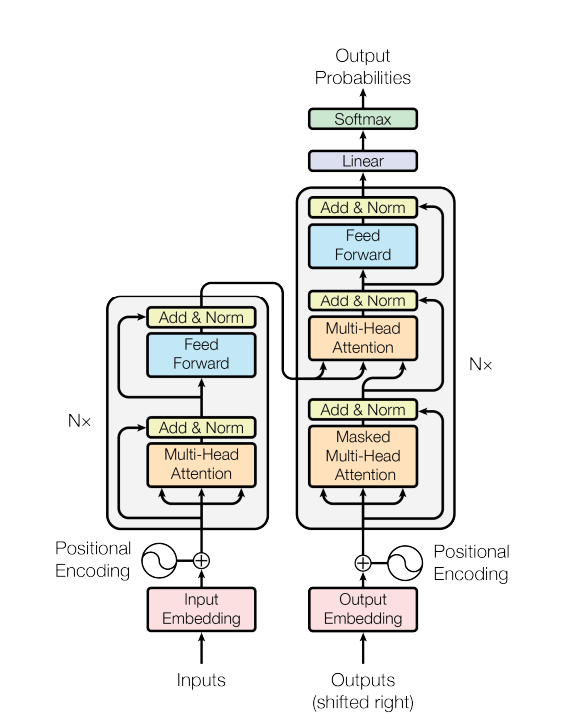
모델은 Encoder / Decoder 크게 두가지 부분으로 나뉘어진다.
그중에서도 Encoder 부분을 먼저 구현하고 Decoder 부분을 구현하는 걸로 하자.
1. Encoder
Decoder 는 크게 Multi-Head-Attention + Position wise Feed-Forward 2가지로 구성되어 있다.
추가적으로, residual 한 부분와 LayerNorm 하는 부분은 forward 에서 구현해 줄 것인데, 일단 Multi-Head-attention 을 먼저 구현하고 나서 차원에 맞춰 구현해보기로 한다.

1-1) Scaled Dot-Product
Multi-Head-Attention 을 구현하기 이전에 Scaled dot product 를 먼저 구현해야 한다.
Multi-head attention 내에서 scale dot-product 계산을 여러개의 head 를 사용하기 때문이다.

scaled dot product 에서 Query , Key , Value 셋 차원이 ( batch_size x (length x d_tensor(dk)) ) 로 생각하고 코드를 작성한다.

<mask>
간단히 설명하고 masking 하는 부분은 뒤에서 다시 설명하도록 하겠습니다.
여기서 masking 은 pad mask로 만약 sentence 부분이 더 짧다면 이를 계산에 추가하지 않기 위해서
매우 작은 값을 넣음으로써 softmax 계산때 확률이 0 에 가깝도록 만드는 원리입니다.
cf. 블로그 안 마지막 그림 참조하면 쉽게 이해 가능 https://code-angie.tistory.com/11
def make_pad_mask(self query, key, pad_idx=1):
# query: (n_batch, query_seq_len)
# key: (n_batch, key_seq_len)
query_seq_len, key_seq_len = query.size(1), key.size(1)
key_mask = key.ne(pad_idx).unsqueeze(1).unsqueeze(2) # (n_batch, 1, 1, key_seq_len)
key_mask = key_mask.repeat(1, 1, query_seq_len, 1) # (n_batch, 1, query_seq_len, key_seq_len)
query_mask = query.ne(pad_idx).unsqueeze(1).unsqueeze(3) # (n_batch, 1, query_seq_len, 1)
query_mask = query_mask.repeat(1, 1, 1, key_seq_len) # (n_batch, 1, query_seq_len, key_seq_len)
mask = key_mask & query_mask
mask.requires_grad = False
return mask
def make_src_mask(self, src):
pad_mask = self.make_pad_mask(src, src)
return pad_mask1-2) Multi-Head-Attention
dmodel 차원의 키, 값, 쿼리를 사용하여 단일 어텐션 함수를 수행하는 대신, dk, dk, dv 차원에 대해 서로 다른 학습된 선형 투영을 사용하여 쿼리, 키, 값을 h번 선형적으로 투영하는 것이 유익하다는 것을 발견했습니다. 이러한 각 투영된 쿼리, 키, 값 버전에서 어텐션 함수를 병렬로 수행하여 dv 차원의 출력 값을 생성합니다. 이러한 값을 연결하고 다시 투영하여 그림 2에 표시된 대로 최종 값을 생성합니다.
멀티헤드 어텐션은 모델이 서로 다른 위치에서 서로 다른 표현 부분 공간의 정보에 공동으로 주의를 기울일 수 있게 해줍니다. 어텐션 헤드가 하나뿐이면 평균화가 이를 억제합니다.

class MultiHeadAttention(nn.Module):
def __init__(self , d_model , head):
super(MultiHeadAttention,self).__init__()
self.head = head
self.attention = ScaleDotProductAttention()
self.wq = nn.Linear(d_model , d_model)
self.wk = nn.Linear(d_model , d_model)
self.wv = nn.Linear(d_model , d_model)
self.out_fc = nn.Linear(d_model , d_model)
def forward(self,q,k,v,mask=None):
'''
q,k,v = (batch_size , length , d_model)
* 여기서 q,k,v 처음에 d_embed 에서 d_k 로 보내지 않았기 때문에 다시 embed 해주는 과정 추가해야 한다.
'''
# 1. dot product with weight matrices
q,k,v = self.wq(q) , self.wk(k) ,self.wv(v) # q,k,v = (batch_size , length , d_model)
# 2. split q,k,v number of head
q = self.split(q) # (batch_size , head ,length , dk)
w = self.split(w)
v = self.split(v)
#3. self attention
out = self.attention(q,k,v,mask)
#4. concat result -> Linear
out = self.concat(out) # (batch_size , legnth , d_model)
out = self.out_fc(out)
return out
def split(self,tensor):
'''
input = [batch_size , length , d_model]
output =[bathc_size , head ,length , dk]
d_model = head x d_k
head 가 앞에 오는 이유는 scaled dot product 에서 계산할때 transpose(-1,-2)를 해서 계산하기 때문
'''
batch_size , length , d_model = tensor.size()
d_k = d_model / self.head
tensor = tensor.view(batch_size , length ,self.head ,d_k).transpose(1,2)
return tensor
def concat(self,tensor)
# split 의 역순으로 조립.
batch_size , head , length , dk = tensor.size()
tensor = tensor.transpose(1,2).view(batch_size, length , head * dk)
return tensor
1-3 ) poisiton wise

구현은 매우 간단하다. Multi-head-attention 에서 나온 output 을 FC layer 에 한번 넣고 ReLU active func에 넣어 준 뒤
다시 FC layer 에 넣어주면 된다.
position wise 는 왜 해주는 것일까?
주요 이유
- 개별 토큰에 대한 독립적인 처리:
- Self-Attention은 모든 토큰 간의 관계를 고려하지만, 그 결과는 여전히 개별 토큰의 벡터로 표현됩니다. Position-wise FFN은 각 토큰의 벡터에 독립적으로 작용하여, 각 토큰에 대한 표현을 개선하고 비선형 변환을 통해 모델의 복잡성을 추가합니다.
- 이 과정에서 각 토큰의 위치에 따라 다른 변환이 적용되므로, 모델이 위치에 따라 다른 특징을 학습할 수 있게 됩니다.
- 비선형성 추가:
- FFN은 비선형 활성화 함수(예: ReLU)를 사용하여 모델에 비선형성을 추가합니다. 이는 모델이 더 복잡한 패턴과 관계를 학습할 수 있도록 합니다.
- Attention 메커니즘은 선형 변환으로 처리되기 때문에, 비선형성을 추가하는 FFN이 필요합니다.
- 표현력 향상:
- FFN은 두 개의 선형 변환(즉, 완전 연결층) 사이에 비선형 활성화 함수를 적용합니다. 첫 번째 선형 변환은 입력 벡터의 차원을 확장하고, 두 번째 선형 변환은 다시 원래의 차원으로 축소합니다. 이렇게 함으로써, FFN은 입력 데이터의 특징을 더욱 풍부하게 표현할 수 있습니다.
- 이 과정은 모델이 더 다양한 패턴을 학습할 수 있도록 돕습니다.
결론
Position-wise Feed-Forward Network는 Self-Attention 메커니즘이 포착하지 못한 복잡한 패턴을 학습할 수 있도록 돕는 중요한 역할을 합니다. 이를 통해 모델이 더 풍부하고 표현력 있는 토큰 임베딩을 생성할 수 있게 되며, 전체 Transformer 모델의 성능을 향상시키는 데 기여합니다
class PositionwiseFeedForward(nn.Module):
def __init__(self , d_model , ff):
super(PositionwiseFeedForward , self).__init__()
liner1 = nn.Linear(d_model , ff)
linear2 = nn.Linear(ff, d_model)
self.relu = nn.ReLU()
def forward(self,x):
out = self.linear1(x)
out = self.ReLU(out)
out = self.linear2(out)
return out
이제 Multi-Head attention 과 FFN 구현이 끝났으니까 위에서 마무리 짓지 못했던 Encoder Block구현을 마무리해보자
class EncoderBlock(nn.Module):
def __init__(self, d_model , head , ff , drop_prob=0.1):
super(EncoderBlock,self).__init__()
self.attention = MultiHeadAttention()
self.ffn = PositionwiseFeedForward()
self.d_model = d_model
self.head = head
self.ff = ff
self.LayerNorm1 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(drop_prob)
self.LayerNorm2 = nn.LayerNorm(d_model)
self.dropout2 = nn.Dropout(drop_prob)
def forward(self,x, src_mask):
# 1. compute self attention
_x = x
x = self.attention(q=x,k=x,v= x,mask)
# 2. add & normalize
x = self.dropout1(x)
x = self.LayerNorm2(x+_x)
# 3. FFN
_x = x
x = self.ffn(x)
# 4. add&norm
x = self.dropout2(x)
x = self.LayerNorm2(x+_x)
return x
class Encoder(nn.Module):
def __init__(self, d_model , head , ff ,drop_prob, n_layers):
'''self.emb = TransformerEmbedding(d_model=d_model,
max_len=max_len,
vocab_size=enc_voc_size,
drop_prob=drop_prob,
device=device)'''
self.layers = nn.ModuleList(
[EncoderBlock(
d_model = d_model ,
head = head ,
ff = ff,
drop_prob = drop_prob) for _ in range(n_layers) ]
)
def forward(self , x, src_mask ):
for layer in self.layers:
x = layer(x, src_mask)
return x
Decoder

class DecoderBlock(nn.Module):
def __init__(self,d_model , head , ff , drop_prob=0.1):
super(DecoderBlock,self).__init__()
self.attention = MultiHeadAttention()
self.LayerNorm1 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(drop_prob)
self.cross_attention = MultiHeadAttention()
self.LayerNorm2 = nn.LayerNorm(d_model)
self.dropout2 = nn.Dropout(drop_prob)
self.ffn = PositionwiseFeedForward()
self.LayerNorm3 = nn.LayerNorm(d_model)
self.dropout3 = nn.Dropout(drop_prob)
def forward(self, x , memory , tgt_mask , src_tgt_mask ):
# 1. cal att + Layer norm
_x = x
x = self.attention(q = x , k = x , v = x , mask = tgt_mask)
x = self.dropout1(x)
x = self.LayerNorm1(x+_x)
#2. cross att
_x = x
x = self.attention(q = x , k = memory , v = memory , mask = src_tgt_mask)
x = self.dropout2(x)
x = self.LayerNorm1(x+_x)
#3. ffn
_x = x
x = self.ffn(x)
x = self.dropout3(x)
x = self.LayerNorm3(x+_x)
return xclass Decoder(nn.Module):
def __init__(self, dec_voc_size, max_len, d_model, ffn_hidden, n_head, n_layers, drop_prob, device):
super().__init__()
self.emb = TransformerEmbedding(d_model=d_model,
drop_prob=drop_prob,
max_len=max_len,
vocab_size=dec_voc_size,
device=device)
self.layers = nn.ModuleList([DecoderLayer(d_model=d_model,
ffn_hidden=ffn_hidden,
n_head=n_head,
drop_prob=drop_prob)
for _ in range(n_layers)])
self.linear = nn.Linear(d_model, dec_voc_size)
def forward(self, trg, src, trg_mask, src_mask):
trg = self.emb(trg)
for layer in self.layers:
trg = layer(trg, src, trg_mask, src_mask)
# pass to LM head
output = self.linear(trg)
return output
Decoder Masking
(cf. encoder masking)
def make_pad_mask(self, query, key, pad_idx=1):
# role : pad 토큰에 대해서 (빈 곳?) masking 해주는 것이다.
# query: (n_batch, query_seq_len)
# key: (n_batch, key_seq_len)
query_seq_len, key_seq_len = query.size(1), key.size(1)
# key.ne(1) --> padiing 토큰을 0 , 나머지를 1로 만들어줌
key_mask = key.ne(pad_idx).unsqueeze(1).unsqueeze(2) # (n_batch, 1, 1, key_seq_len)
key_mask = key_mask.repeat(1, 1, query_seq_len, 1) # (n_batch, 1, query_seq_len, key_seq_len)
query_mask = query.ne(pad_idx).unsqueeze(1).unsqueeze(3) # (n_batch, 1, query_seq_len, 1)
query_mask = query_mask.repeat(1, 1, 1, key_seq_len) # (n_batch, 1, query_seq_len, key_seq_len)
mask = key_mask & query_mask # and 연산
mask.requires_grad = False
return mask
def make_src_mask(self, src):
pad_mask = self.make_pad_mask(src, src)
return pad_mask
(decoder masking)
def make_subsequent_mask(query, key):
# role : decoder 에서 학습할때 자기 순번 이상의 토큰을 보지 못하게 하기 위함이다.
# query: (n_batch, query_seq_len)
# key: (n_batch, key_seq_len)
query_seq_len, key_seq_len = query.size(1), key.size(1)
tril = np.tril(np.ones((query_seq_len, key_seq_len)), k=0).astype('uint8')
mask = torch.tensor(tril, dtype=torch.bool, requires_grad=False, device=query.device)
return mask
def make_tgt_mask(self, tgt):
pad_mask = self.make_pad_mask(tgt, tgt)
seq_mask = self.make_subsequent_mask(tgt, tgt)
mask = pad_mask & seq_mask
return pad_mask & seq_mask
# src - tgt mask.
# encoder - k ,v 와 decoder 의 q 를 위한 마스킹임.
def make_src_tgt_mask(self, src, tgt):
pad_mask = self.make_pad_mask(tgt, src)
return pad_mask
decdoer 에서는 encoder 와는 조금 다르게 masking 해준다.
(Future Token mask)
decoder 에서 self-attention 연산을 할 때
i 번째 토큰을 생성할때 1~i-1 번째 토큰 까지만 참조 할 수 있어야 하기 때문에 이후를 보이지 않게 masking 하는 것이다.
그걸 구현한게 make_subseqeunt_mask 이다.하지만 이 뿐만 아니라 pad masking 역시 encoder 와 마찬가지로 해야 하기 때문에 make_pad_masking 역시 사용해서 tgt_mask 를 만들어줍니다.
(Padding mask)
make_src_tgt_mask 는 cross-attention 에서 사용하게 됩니다.( Decoder 내에서 encoder output context vector 를 가지고 attention 을 계산하는 것을 의미함) -> (query : decoder self-att 에서 나온 vector / key,value : encoder output vector)
이 두가지 벡터는 서로 다른 벡터길이(ex 영어/한국어)를 가지기 때문에 pad masking 을 해주게 됩니다.
Q : 왜 첫번째에는 subsquence mask 하면서 두번째에는 적용하지 않을까?
2. Decoder의 Self-Attention (First Self-Attention Layer in Decoder)
- 마스킹 종류: Future Masking + Padding Masking
- 이유:
- 디코더의 Self-Attention은 현재 시점까지의 단어들만을 사용하여 다음 단어를 예측해야 합니다. 이를 위해 미래의 단어를 보지 못하도록 Future Masking을 적용합니다.
- 동시에, 입력 시퀀스에서 패딩 토큰을 무시하기 위해 Padding Masking도 적용됩니다.
- 결과적으로, 디코더의 Self-Attention은 현재 시점까지의 단어와 패딩되지 않은 단어들만을 고려하여 학습합니다.
3. Decoder의 Cross-Attention (Encoder-Decoder Attention)
- 마스킹 종류: Padding Masking
- 이유:
- 디코더의 Cross-Attention은 디코더의 현재 상태와 인코더의 출력 간의 관계를 학습합니다. 이 과정에서 인코더의 출력 시퀀스에서 패딩 토큰이 있는 경우 이를 무시해야 합니다.
- Cross-Attention은 인코더의 출력 전체를 참조하지만, 패딩된 위치의 정보는 유효하지 않으므로 Padding Masking만 적용합니다.
핵심 포인트
- 미래 마스킹 (Future Masking):
- 디코더의 Self-Attention에서만 사용됩니다.
- 디코더는 현재 시점의 단어만을 보고 다음 단어를 예측해야 하므로 미래 단어를 보지 않도록 합니다.
- 패딩 마스킹 (Padding Masking):
- 모든 Self-Attention과 Cross-Attention에서 사용됩니다.
- 패딩된 토큰이 실제 단어와 섞이지 않도록 하여 학습에 영향을 미치지 않게 합니다.
결론
디코더의 Cross-Attention에서는 인코더의 전체 출력 시퀀스를 참조하지만, 패딩된 토큰을 무시하기 위해 Padding Masking을 사용합니다. 반면에 디코더의 Self-Attention에서는 현재 시점까지의 단어만을 보고 다음 단어를 예측해야 하므로 Future Masking과 Padding Masking을 함께 사용합니다. 이를 통해 디코더는 적절한 정보를 학습하고 예측할 수 있게 됩니다.
(reference)
https://moondol-ai.tistory.com/46
https://www.blossominkyung.com/deeplearning/transfomer-positional-encoding
(*)
https://cpm0722.github.io/pytorch-implementation/transformer
https://github.com/hyunwoongko/transformer?tab=readme-ov-file
(1블로그에 원조글 harvard nlp)
http://nlp.seas.harvard.edu/2018/04/03/attention.html
2) encoder 구현시 참고 블로그
ViT 구현하기
1) https://deep-learning-study.tistory.com/807
[논문 구현] ViT(2020) PyTorch 구현 및 학습
공부 목적으로 ViT를 구현하고 학습한 내용을 공유합니다 ㅎㅎ. 작업 환경은 Google Colab에서 진행했습니다. 필요한 라이브러리를 설치 및 임포트합니다. !pip install einops import torch import torch.nn as nn i
deep-learning-study.tistory.com
부족한부분 & 헷갈렸던 부분 :
1. 처음부터 모든걸 고려하고 구현하려고 하니 애를 많이 먹었다. --> 직접 구현을 해보니 큰 그림을 어느정도 그려놓고 (얼만큼 디테일 한지는 본인 능력및 경험에따라 달라지는듯?) 세부적인걸 작성한다음 다시 조금씩 수정하기.
2. 차원 관리에서 좀 헷갈렸다. --> 이부분은 구현을 자주 하고 논문을 좀 더 디테일하게 읽었다면 조금 더 쉽게 해볼 수 있지 않을까. 또 여기서 썼던 기술들(np.trill , view() 로 차원이동하기..) 을 잘 익혀두면 계속 사용하지 않을까
3. 논문을 읽고 나서 이해가 됐다고 생각했는데 막상 해보니 그게 아니였다는걸 절실히 알았다.
특히 논문에 없는 디테일들을 직접 구현하려고 하니 더 쉽지 않았다.
이후에는 Transformer 를 사용한 vit 나 Yolo or CNN 사용 모델을 구현하려고 한다.