
Momentum encoder -> moco 논문 읽기
논문에서 제기하는 문제점
1. encoder base 모델
(ex : CLIP)
이해 기반 작업에 강점이 있음 ( 이미지-텍스트 검색)
but, 텍스트 생성 작업에서 비효율적임.
입력 데이터를 임베딩한 후에 generation 과정에서 추가의 디코더를 필요로함.
2. encoder-decoder base 모델
생성 기반 작업에 강점 ( 이미지 캡션 생성 )
but, 이미지와 텍스트 간의 bidirectional matching 수행하기 적합하지 않음.
이미지와 텍스트를 직접 비교하는 대신, 텍스트를 이미지 기반으로 디코딩 과정을 거치기 때문에 검색에 용이하지 않음.
3. dataset
기존 데이터 셋에 noise 가 너무 많이 껴있음.
해결책
BLIP 의 모델은 MED(Multimodal Mixture of Encoder-Decoder)이다. MED 모델은 세가지 방식으로 작동하는데
1.Unimodal Encoder : 텍스트,이미지 서로 독립적으로 인코딩
2. Image-grounded Text Encdoer : 이미지기반으로 텍스트 이해
3. Image grounded Text Decoder : 이미지 -> 텍스트 생성
검색과 generation 작업을 하나의 모델로 통합.

1. ITC ( Image-Text Contrastive Learning )
2. ITM ( Image-Text Matching ) : binary classification. ( image-text matching )
3. LM ( Image-Conditioned Language Modeling )
Data 관점
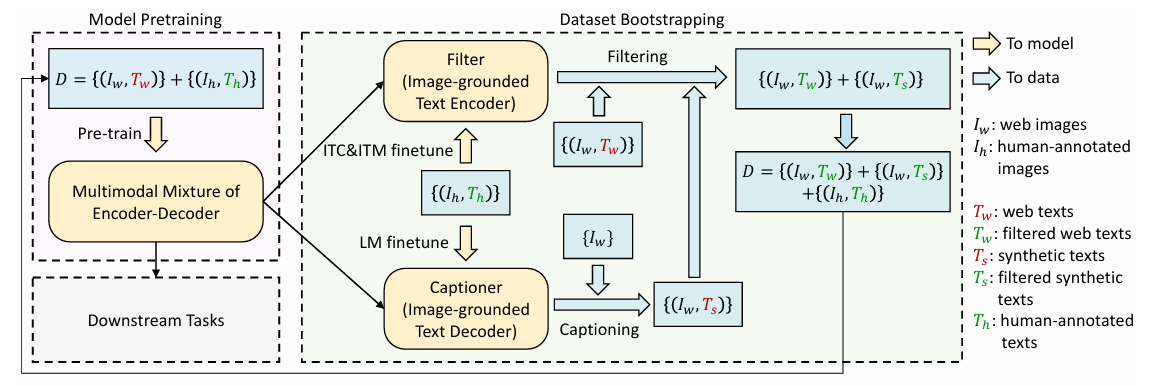
CapFilt ( Bootstrapping )
1. caption : 이미지로부터 synthetic caption 생성 ( 기존 텍스트가 부정확하거나 노이즈가 많을 때 대체)
2. Filter : synthetic caption 과 기존 웹 텍스트에서 noise 제거. ( 말그대로 필터 역할 )
ㄴ> 사전 학습된 MED 를 captioner 와 Filter 로 fine-tuning.
- 기존 데이터가 부족하거나 부정확한 상황에서도 활용 가능.
- 점진적인 개선을 통해 모델의 범용성과 성능 모두를 증진
- 기존 Encoder-Decoder 모델:
- 생성 작업(이미지 → 텍스트)에 강점.
- 양방향 검색(텍스트 ↔ 이미지) 작업은 비효율적.
- BLIP의 MED 모델:
- 생성과 검색 작업 모두를 하나의 모델에서 통합적으로 수행.
- 이미지 ↔ 텍스트 매칭에서도 효율적이고 정확한 결과를 달성.
1. ITC ( Image-Text Contrastive Learning )
Unimodal encoder - 텍스트와 이미지를 각각의 encoder에 넣는다.
이후 clip 처럼 contrastive learinng 을 실행한다.
Image Encoder와 Text Encoder로부터 나온 임베딩을 공통 임베딩 공간으로 매핑.
We follow the ITC loss by Li et al. (2021a), where a momentum encoder is introduced to produce features, and soft labels are created from the momentum encoder as training targets to account for the potential positives in the negative pairs. ( 여기서 momentum encoder 가 정확히 뭘 의미하는지 잘 모르겠음 , 쓰면 학습에 용이하다고 하는 것 같기는 한데..)
-> Momentum Encoder가 Base Encoder의 이전 상태를 조금씩 반영하도록 만든다.
CF.
Momentum Encoder는 BLIP에서 중요한 역할을 담당하는 구성 요소로, 이미지-텍스트 데이터의 관계를 더욱 안정적이고 강력하게 학습하기 위해 사용됩니다. 이를 이해하기 위해, 먼저 Momentum Encoder의 개념과 역할, 그리고 BLIP에서의 활용 방식을 자세히 설명하겠습니다.
Momentum Encoder란?
Momentum Encoder는 일반적인 학습 과정에서 사용되는 **기본 모델(Base Encoder)**와는 다르게, 업데이트 방식이 다소 느리게(more slowly) 진행되는 모델입니다. 이는 주로 Consistency Regularization이나 Contrastive Learning과 같은 기법에서 사용되며, 다음과 같은 목적을 가집니다:
- 모델 업데이트 안정성 확보: 기본 모델이 매 학습 단계마다 크게 업데이트되는 반면, Momentum Encoder는 더 완만하게 업데이트되어, 학습 과정에서의 급격한 변화(노이즈)를 줄입니다.
- 보다 안정적인 표현 학습: 이미지와 텍스트 간의 관계를 학습하는 과정에서, 보다 일관된 피처 표현을 유지할 수 있습니다.
Momentum Encoder의 업데이트 방식
Momentum Encoder는 일반적으로 **Exponential Moving Average (EMA)**를 통해 업데이트됩니다. 이는 기본 모델(Base Encoder)의 가중치를 따라가지만, 완전히 동일하게 복사하지는 않고, 일정 비율(β\beta)로 가중치를 섞습니다.
수식으로 나타내면:
θm←β⋅θm+(1−β)⋅θ\theta_m \leftarrow \beta \cdot \theta_m + (1 - \beta) \cdot \theta
여기서:
- θm\theta_m: Momentum Encoder의 가중치
- θ\theta: Base Encoder의 가중치
- β∈[0,1]\beta \in [0, 1]: Momentum Coefficient (보통 β\beta는 0.99 또는 그 이상으로 설정)
이 방식은 Momentum Encoder가 Base Encoder의 이전 상태를 조금씩 반영하도록 만듭니다. 따라서 갑작스러운 변화를 방지하고 더 부드러운 업데이트를 가능하게 합니다.
Momentum Encoder의 BLIP에서의 역할
BLIP에서는 Momentum Encoder가 Contrastive Learning 과정에서 중요한 역할을 합니다.
- 이미지-텍스트 매칭 학습:
- Momentum Encoder는 이미지와 텍스트 간의 정확한 연결 관계를 학습하는 데 사용됩니다.
- 기본 모델(Base Encoder)을 학습시키는 동안, Momentum Encoder는 이미지와 텍스트 피처의 안정적인 표현을 제공하여, 과적합이나 학습 노이즈를 줄입니다.
- 양질의 Negative Sampling 제공:
- Contrastive Learning에서 양질의 Negative Pair(잘못된 이미지-텍스트 쌍)를 생성하기 위해 사용됩니다.
- Momentum Encoder는 기본 모델보다 업데이트가 느려, 현재의 Base Encoder와 약간 다른 표현을 생성합니다. 이는 더 다양하고 효과적인 Negative Pair를 만들 수 있도록 돕습니다.
- Cross-Attention과의 결합:
- Momentum Encoder는 Vision Encoder와 Text Encoder에서 각각 독립적으로 학습된 피처를 활용해, Cross-Attention에서 더 강력한 멀티모달 표현을 형성합니다.
왜 Momentum Encoder를 사용하는가?
- Contrastive Learning의 안정성:
- Contrastive Learning에서는 이미지와 텍스트 임베딩의 간격을 조정하여 관계를 학습합니다. 하지만 기본 모델이 너무 빠르게 업데이트되면, Negative Pair의 질이 떨어질 수 있습니다.
- Momentum Encoder는 이러한 과적합이나 학습 노이즈를 방지합니다.
- 멀티모달 학습의 일관성 유지:
- 이미지는 시간이 지나도 그 의미가 크게 바뀌지 않기 때문에, Momentum Encoder를 사용하여 안정적인 이미지 표현을 유지할 수 있습니다.
- 텍스트도 마찬가지로, 동일한 컨텍스트 내에서 안정성을 갖춘 표현이 필요합니다.
BLIP의 Momentum Encoder 구현과 활용
BLIP에서는 Momentum Encoder를 다음과 같이 활용합니다:
- 학습 데이터:
- 이미지와 텍스트의 쌍을 입력으로 사용.
- Momentum Encoder는 이 데이터를 기반으로 임베딩을 생성.
- Loss 계산:
- Base Encoder의 출력과 Momentum Encoder의 출력을 비교하며 Contrastive Loss를 계산.
- Momentum Encoder의 출력을 **"기준"**으로 삼아, Base Encoder가 더욱 좋은 피처를 학습하도록 유도.
- 이점:
- Contrastive Learning의 성능을 크게 향상.
- 데이터 노이즈의 영향을 최소화하여 학습 과정의 안정성 증가.
요약
Momentum Encoder는 BLIP에서 이미지-텍스트 관계를 학습할 때, 안정성과 성능 향상을 위해 사용되는 핵심적인 구성 요소입니다. Base Encoder보다 업데이트 속도가 느리며, Contrastive Learning에서 보다 정교하고 안정적인 학습을 가능하게 만듭니다.
추가적인 질문이나 더 알고 싶은 점이 있다면 말씀해주세요! 😊
2. ITM
- 목적:
- 이미지와 텍스트 쌍이 의미적으로 일치하는지 여부를 이진 분류로 학습.
- 과정:
- ITC로 생성된 긍정 및 부정 샘플(Positive/Negative Samples)을 사용 --> Binary Cross Entropy Loss.
- Vision Encoder와 Text Encoder의 출력 임베딩을 조합.
- 분류기를 통해 이미지-텍스트 쌍의 일치 여부를 예측.
- 결과:
- 이미지-텍스트 매칭 성능 향상.
Image-Text Matching (ITM)는 이미지와 텍스트 쌍이 "매칭"되었는지 여부를 예측하는 이진 분류 작업입니다. ITM은 **이미지와 텍스트의 세밀한 정렬(fine-grained alignment)**을 학습하여 멀티모달 표현을 효과적으로 생성하는 데 초점을 맞춥니다.
ITM의 주요 개념
- 학습 목표:
- 이미지와 텍스트 쌍이 올바른 매칭인지 ("positive pair") 또는 잘못된 매칭인지 ("negative pair")를 분류.
- 이미지와 텍스트 간의 정확한 정렬을 이해하고, 이를 멀티모달 임베딩 공간에서 표현.
- 활성화되는 모듈:
- ITM 과정에서는 Image-Grounded Text Encoder가 활성화됩니다. 이 모듈은 Cross-Attention을 사용하여 이미지 정보를 텍스트 임베딩에 주입합니다.
- ITM Head:
- ITM 작업을 수행하기 위해 Linear Layer로 구성된 ITM Head를 사용.
- ITM Head는 멀티모달 임베딩을 받아 매칭 여부를 이진 분류하는 역할을 합니다.
학습 과정
ITM 학습 과정은 다음과 같습니다:
1. 이미지와 텍스트 임베딩 생성
- 이미지는 Image Encoder를 통해 임베딩 벡터로 변환됩니다.
- 텍스트는 Text Encoder를 통해 임베딩 벡터로 변환되며, 중간에 Cross-Attention이 추가되어 이미지 정보를 주입받습니다.
- 이 과정에서 텍스트 임베딩은 이미지-텍스트 간의 정렬을 더 잘 반영하도록 학습됩니다.
2. 멀티모달 임베딩 생성
- 이미지 임베딩과 텍스트 임베딩을 결합하여 하나의 멀티모달 임베딩 벡터를 생성합니다.
- 결합 방식은 이미지와 텍스트 임베딩을 단순히 이어 붙이거나, Cross-Attention을 통해 더욱 복합적으로 결합하는 방식이 될 수 있습니다.
3. ITM Head를 통해 매칭 여부 예측
- 멀티모달 임베딩 벡터는 ITM Head (Linear Layer)에 입력됩니다.
- ITM Head는 이 벡터를 기반으로 매칭 여부를 확률값으로 출력합니다:
- 1: 이미지와 텍스트 쌍이 매칭됨.
- 0: 이미지와 텍스트 쌍이 매칭되지 않음.
- Binary Cross-Entropy Loss를 사용하여 Loss를 계산하고, 모델의 가중치를 업데이트합니다.
Hard Negative Mining 전략
ITM 학습에서는 Hard Negative Mining을 도입하여 더 어려운 부정 예제를 선택해 모델 성능을 향상시킵니다.
- Hard Negative의 정의:
- 부정 쌍(negative pair) 중에서도, 이미지와 텍스트 간의 Contrastive Similarity가 높은 쌍을 Hard Negative로 정의.
- 예를 들어, 부정 쌍 중에서도 "비슷한 의미를 가진 텍스트" 또는 "유사한 시각적 특징을 가진 이미지"가 포함된 쌍.
- Hard Negative Mining의 과정:
- Contrastive Similarity (e.g., Cosine Similarity)를 사용하여 모든 이미지-텍스트 쌍의 유사도를 계산.
- 유사도가 높은 부정 쌍을 선택해 Loss 계산에 사용.
- 이를 통해 모델이 더 어렵고 구체적인 예제를 학습하도록 유도.
- 효과:
- Hard Negative Mining은 모델이 단순히 쉬운 부정 쌍을 구별하는 데 머물지 않고, 더 어려운 예제에서도 정확한 매칭 여부를 예측하도록 만듭니다.
- 이는 ITM 학습 과정의 효율성과 일반화 성능을 크게 향상시킵니다.
ITM의 중요성
- ITM은 Contrastive Learning (ITC)과 달리, 이미지와 텍스트 간의 세밀한 관계를 학습합니다.
- Contrastive Learning이 글로벌 유사도를 학습하는 데 중점을 둔다면, ITM은 멀티모달 표현의 로컬 특징을 반영하도록 모델을 최적화합니다.
- 이는 BLIP 모델이 이미지-텍스트 매칭, 이미지 캡션 생성, VQA 등 다양한 다운스트림 태스크에서 높은 성능을 발휘하는 데 기여합니다.
3. LM
- 목적:
- 이미지를 조건으로 텍스트(예: 캡션)를 생성.
- 과정:
- Vision Encoder가 이미지를 임베딩으로 변환.
- Text Decoder가 이미지 임베딩을 조건으로 텍스트를 생성.
- 결과:
- 이미지 캡션 생성, VQA 같은 생성 중심 작업에서 활용.
autogressive 방식으로 텍스트 생성,
label smoothing 적용함 . (https://ratsgo.github.io/insight-notes/docs/interpretable/smoothing)
이 부분은 **Language Modeling Loss (LM)**와 관련된 내용을 설명하며, BLIP 모델에서 텍스트 디코더가 어떻게 학습되고, 텍스트 인코더와 디코더가 어떤 구조적 특성을 공유하며 협력하는지에 대해 다루고 있습니다. 자세히 하나씩 살펴보겠습니다.
1. Language Modeling Loss (LM)란?
LM Loss는 텍스트 디코더가 이미지에서 텍스트를 생성하도록 학습하는 과정에서 사용됩니다. 이는 기존의 **Masked Language Modeling (MLM)**과 비교해 텍스트 생성에 초점이 맞춰져 있습니다.
LM Loss의 목적
- 이미지 정보를 기반으로 연속적이고 의미 있는 텍스트를 생성하도록 디코더를 학습.
- 학습 목표는 주어진 이전 토큰(이미 생성된 텍스트)과 이미지 임베딩을 조건으로 다음 토큰의 확률을 최대화하는 것입니다.
Cross-Entropy Loss
LM Loss는 Cross-Entropy Loss를 사용합니다. 아래와 같은 방식으로 계산됩니다:
LLM=−∑t=1TlogP(yt∣y1:t−1,image)\mathcal{L}_{LM} = -\sum_{t=1}^T \log P(y_t | y_{1:t-1}, \text{image})- yty_t: 타겟 텍스트의 tt번째 토큰.
- y1:t−1y_{1:t-1}: 이전까지 생성된 텍스트.
- image\text{image}: 이미지 임베딩.
레이블 스무딩(Label Smoothing):
- 레이블 스무딩(0.1)을 적용해 모델이 너무 높은 확신으로 예측하지 않도록 정규화 효과를 줍니다.
- 즉, 정답 토큰 외의 다른 토큰에 대해 약간의 확률을 부여해 과적합을 방지합니다.
+) 텍스트 인코더,디코더의 구조적 특성 공유 및 협력 방식
2. 텍스트 인코더와 디코더의 관계
BLIP에서는 텍스트 인코더와 디코더가 대부분의 매개변수를 공유합니다. 하지만 Self-Attention (SA) 레이어만 별도로 사용합니다. 이는 인코더와 디코더가 각각 다른 작업(인코딩 vs. 디코딩)을 수행하기 때문입니다.
공유되는 레이어
- Embedding Layer: 텍스트를 임베딩 벡터로 변환.
- Cross-Attention (CA) Layer: 이미지 정보를 통합.
- Feed Forward Network (FFN): 최종 임베딩 변환.
분리된 레이어
1. 인코더의 Bi-directional Self-Attention
- 양방향으로 토큰 간 관계를 학습합니다.
- 전체 입력 텍스트를 한 번에 관찰하며, 각 토큰의 의미를 문맥에 맞게 이해합니다.
2. 디코더의 Causal Self-Attention
- 순방향(오른쪽 방향)으로만 토큰을 예측합니다.
- 디코더는 이전 토큰(생성된 텍스트)과 이미지를 기반으로 다음 토큰을 예측합니다.
- 이를 통해 오토리그레시브 텍스트 생성이 가능합니다.
3. 인코딩과 디코딩의 차이를 고려한 설계 이유
효율성과 다중 작업 학습의 이점
- 효율성:
- 대부분의 레이어를 공유함으로써, 모델 크기를 줄이고 학습 비용을 절감합니다.
- 특히 VLP(비전-언어 사전 학습)에서 멀티태스킹을 위한 자원 사용을 최적화합니다.
- 다중 작업 학습의 시너지:
- 인코더와 디코더가 같은 임베딩 및 FFN 레이어를 공유하면서도 각자의 작업에 특화된 SA 레이어를 사용해 공유와 분리의 균형을 유지합니다.
- 이는 서로 다른 작업(이해 vs. 생성) 간의 일반화를 개선합니다.
4. LM Loss의 차별성
BLIP에서 LM Loss는 기존 MLM Loss와 다음과 같은 차이를 보입니다:
- MLM은 텍스트 이해에 초점:
- 일부 토큰을 마스킹하고, 이를 복원하도록 학습.
- 예) 텍스트의 빈칸 채우기(The cat is [MASK]).
- LM은 텍스트 생성에 초점:
- 전체 문장을 생성하며, 이미지 정보를 활용.
- 예) 이미지 기반으로 텍스트 캡션 생성(A cat is sitting on a chair).
+)
MLM (Masked Language Modeling)
MLM은 주로 텍스트 이해에 중점을 둔 학습 방식입니다.
동작 방식
- 입력 텍스트의 일부 토큰을 마스킹([MASK])합니다.
예:
입력 → The cat is [MASK] on the chair.
타겟 → [sitting] - 모델은 마스킹된 토큰을 주변 문맥(양방향)을 활용하여 예측합니다.
- 양방향 문맥: 마스킹된 단어를 중심으로, 이전과 이후의 모든 단어 정보를 활용.
주요 특징
- 텍스트 이해를 위한 학습에 특화:
모델이 입력 텍스트 전체의 의미와 문맥을 이해하도록 학습합니다. - 비생성적(task-specific): 마스킹된 단어만 예측하며, 새로운 문장을 생성하지 않습니다.
LM (Language Modeling)
LM은 주로 텍스트 생성에 중점을 둔 학습 방식입니다.
동작 방식
- 텍스트를 오토리그레시브(autoregressive) 방식으로 학습합니다.
- 입력 토큰을 조건으로 다음 토큰을 순차적으로 예측.
예:
입력 → The cat is
타겟 → sitting
- 입력 토큰을 조건으로 다음 토큰을 순차적으로 예측.
- 모델은 순방향(왼쪽에서 오른쪽) 문맥만 활용해 다음 토큰을 생성합니다.
- 이전에 생성된 토큰을 조건으로 하여 다음 단어를 예측합니다.
주요 특징
- 텍스트 생성에 특화:
입력 정보(예: 이미지)와 이전 토큰을 활용해 새로운 문장을 생성합니다. - 생성적(generative): 모델이 전체 문장을 순차적으로 생성할 수 있습니다.
MLM과 LM의 핵심 차이점
특징MLM (Masked Language Modeling)LM (Language Modeling)| 학습 목적 | 텍스트 이해 및 복원 | 텍스트 생성 |
| 문맥 활용 방식 | 양방향 (Bidirectional) | 순방향 (Unidirectional) |
| 입력 토큰 처리 | 일부 토큰 마스킹([MASK]) | 모든 이전 토큰을 입력으로 사용 |
| 생성 가능성 | 비생성적 (마스킹된 토큰만 예측) | 생성적 (전체 문장을 생성) |
| 적용 가능 작업 | 텍스트 이해, 분류, 빈칸 채우기 | 캡션 생성, 텍스트 생성, 번역 |
BLIP에서의 LM 적용
BLIP에서는 LM을 사용하여 이미지 정보를 조건으로 새로운 텍스트를 생성합니다.
MLM 대신 LM을 선택한 이유는, 텍스트 생성(캡션 생성) 작업을 수행하기 위해 순차적인 오토리그레시브 텍스트 생성이 필요하기 때문입니다.
결론
- MLM은 일부 토큰을 예측하며 텍스트 이해와 복원에 중점을 둡니다.
- LM은 새로운 문장을 생성하며, 텍스트 생성에 초점이 맞춰져 있습니다.
- BLIP의 LM Loss는 캡션 생성과 같은 작업에 적합하도록 설계되었습니다.
추가적으로 궁금한 점이 있다면 질문해주세요! 😊
Capfilt
'Paper' 카테고리의 다른 글
| VGGT 발표자료 (0) | 2025.08.16 |
|---|---|
| MMaDA 논문 발표자료 (2) | 2025.08.06 |
| [paper review] Meshed-Memory Transformer (3) | 2024.12.24 |
| MViTv2: Improved Multiscale Vision Transformers for Classification and Detection 리뷰 (2) | 2023.09.26 |
| ViViT: A Video Vision Transformer 리뷰 (0) | 2023.09.08 |