

( 3.3.4 Why DSM is Denoising: Tweedie’s Formula 부분 수정 필요 )
이번 챕터에서는 이제 Energy-Based Model 부터 NCSN 을 배우게 됩니다.
이전에 다루었던 VAE 관점에서 벗어나서 , 데이터를 Energy landscape 와 Gradient 를 통해 해석하는 방식을 배웁니다.
1. 에너지 기반 모델 (EBM)
데이터의 분포를 에너지 지형으로 표현
낮은 에너지 : 실제 데이터가 존재하는 곳 ( 확률 밀도가 높음 )
높은 에너지 : 데이터가 아닌 노이즈가 있는곳 ( 확률 밀도가 낮음 )
즉 , 생성 모델의 목표는 이 에너지 지형을 학습하여 , 에너지가 낮은 골짜기가 어디인지 알내는 것입니다.
2. Langevin Dynamics 과 score
데이터 생성(샘플링) 하는 과정이 Langevin Dynamics 을 따른다. 에너지가 낮은 방향 ( 데이터가 있을 확률이 높은 방향) 으로 조금씩 이동
score : 이동해야 할 방향을 알려주는 역할. (수학적으로는 확률 밀도 함수의 기울기 )
전체 확률 분포를 정확히 알 필요 없이 , 어느 쪽으로 가야 더 진짜같은 데이터가 되는지 기울기만 알면 데이터를 생성할 수 있습니다.
3. Score-based Diffusion Models
기존 방식은 데이터가 없는 영역에서는 스코어를 정확히 추정하기 어렵다는 단점이 있었는데 , 확산 모델은 노이즈 추가 , 벡터 필드 학습 , 점진적 디노이징 같은 방식으로 해결합니다.
이제 본격적으로 더 깊게 알아보도록 하겠습니다.
3.1 Energy-Based Models
위 논문에서는 설명되어 있지 않지만 먼저 들어가기 앞서 Energy based models 에 대한 기본 컨셉을 이해해보고자 합니다.
( 위 블로그 참고 )
https://process-mining.tistory.com/215
물리학에서 시스템이 가장 에너지가 가장 낮은 상태로 가려는 성질이 있는데 (엔트로피도 그렇고. ) EBM 은 이 원리를 확률 분포에 이식한것 입니다.
에너지 E(x) : 데이터 x 가 진짜 데이터와 얼마나 거리가 먼지 나타내는 척도
실제 데이터 = 에너지 낮음
noisy 한 데이터 = 에너지 높음
1) EBM 의 정의 : 확률 = exp(-에너지) / z

데이터 x 에 대해서 에너지함수 E(x) 를 학습합니다.
- exp(-E ) : 에너지가 낮을수록 -> 값이 커짐 -> 확률(p) 가 커짐
- z : 정규화 상수
하지만 딱 봐도 z 자체가 계산하기 어려운 문제가 보이죠 ?
( 디퓨전에서도 그렇고 이를 잘 우회하기 위해서 많은 기법을 사용했습니다. )
2) 에너지는 상대값만 의미가 있다 ( 상수항을 건드려도 분포는 동일하다 )

1. 에너지를 바꾼다고 가정해봅시다 ( +c )
2. 그러면 분자는 다음과 같이 변하고
3. 분모도 다음과 같이 변하게 됩니다.
4. 따라서 확률을 계산해 봤더니 ..? -> 결국 같습니다.
그래서 수식적으로 EBM 에서 중요한게 "에너지의 절댓값" 이 아니라 에너지의 "상대적" 차이가 중요한 것을 알 수 있습니다.
3.1.1 Modeling Probability Distributions Using Energy Functions
위에서 설명한것과 동일하게 EBM 은 에너지 함수 Eϕ(x)를 다음과 같이 정의합니다.

exp(-Eϕ(x)) : 점수
- 에너지가 낮을수록 -> exp 커짐 => 낮은 에너지 (= 높은 확률 )
z : 정규화 상수

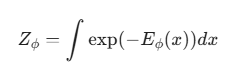
그리고 위에서 이야기 했듯이 , EBM 에서는 에너지의 절대적인 값 보다 에너지의 상대값만 의미가 있습니다.
하지만 여기서 하나의 문제점이 있는데 Global trade-off 라는 문제점이 있습니다 ( 풍선효과 )
비유를 해보자면 풍선의 한쪽을 누르면 풍선의 공기는 한정되어 있기 때문에 다른 한쪽이 반드시 튀어나와야 합니다.
마찬가지로 EBM 은 특정 지역의 확률을 독립적으로 할당하는게 아니라 적분해서 값이 1 이기 때문에 , 한 지점의 에너지를 낮추는 순간 -> 나머지 지점들의 위치를 상대적으로 높게 만들게 됩니다.
이 global trade off 때문에 EBM 을 학습시키기가 매우 어렵다고 합니다. ( 나머지 모든곳의 에너지를 골고루 높여야 되기 때문 . )

Challenges of Maximum Likelihood Training in EBMs.
EBM 을 MLE 로 학습하기 위해서 수식을 다음과 같이 분해하면

poisitve phase ( lowers energy of data )
- 실제 데이터 샘플을 가져와서 그 지점의 에너지를 낮추는 방향으로 업데이트 함 (계산 쉬움)
Negative phase
- 정규화(전체 적분 1 ) 이 깨지지 않도록 전역적으로 균형을 맞추는 부분 ( 아까 말한 global regularization )
- 계산하기 어렵다. ( intractable )
log z 의 미분을 전개해보면 다음과 같은데

결국 미분을 하고 나니 x∼pϕ에서 샘플을 뽑아야 계산을 할 수 있는 형태로 나오게 됩니다.
pϕ 를 MC 로 샘플링을 직접 해야하는데 , 이게 매우 어려운 일라고 합니다.
( cf . Diffusion policy 에서도 이런 언급을 했었습니다 . - negative sample 이 있어야 하는 단점이 있다 . )
3.1.2 Motivation:What Is the Score?
( 핵심 : 확률 밀도 P(x) 를 그 자체로 맞추기 보다 , 그 로그의 기울기 ( = 스코어 ) 를 맞추면 훨씬 일이 쉬워진다. ! )
1. Score 의 정의

확률 밀도 p(x) 가 있을때 score 는 다음과 같이 정의됩니다.
- log p(x) 를 지형의 높이라고 한다면 score 는 가장 가파르게 높아지는 방향을 가리키는 벡터입니다.
- 기울기x(스코어) 는 x를 조금 움직였을때 log p 가 가장 빨리 증가하는 방향을 알려줍니다.
- 그래서 스코어 벡터장은 공간 전체에서 여기서 어디로가면 더 확률이 높은 데이터의 영역인지 알려주는 가이드 같은 역할을 하게 됩니다.
( 아래 그림 참조 )
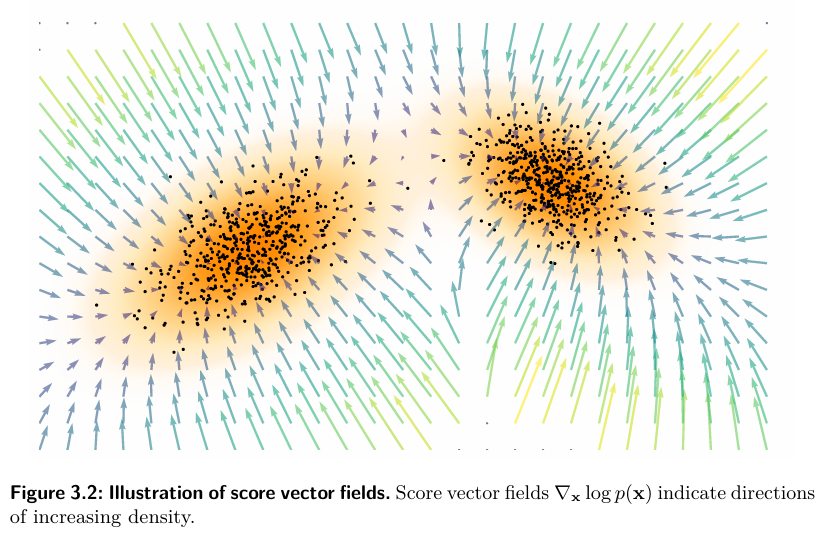
딥러닝 처음 공부할때 gradient 에서 보던 그림들이랑 매우 유사하죠?
Why Model Scores Instead of Densities?
왜 density 대신 score 를 모델링 하는지 설명합니다.
1. 정규화 상수 z 에서 자유롭다.
2. 스코어는 분포를 완전히 표현한다.
1. Freedom from Normalization Constants.
정규화 상수 z 에 대해서 자유롭게 됩니다.
EBM 이면 위에서 본 수식과 동일하지만

Score 를 보면 ( 정의에 있는 수식 그대로 가지고 온것 )

log z 가 x 에 대한 상수라서 미분하면 사라지게 됩니다.
원래 density 학습(MLE) 는 log Z 때문에 막히지만 , Score 학습은 log Z 를 원칙적으로 bypass 할 수 있게됩니다.
2. A Complete Representation.
score s(x) ( log p 미분값 / 기울 ) 을 모든 x 에 대해서 알고 있다면 , log p(x) 를 전부 복원이 가능해 집니다.
( 적분하면 상수가 나오지만 , 마지막 상수의 값은 적분한p 값 = 1 이라는 성질을 통해서 결정가능해 집니다. )
( 너무 간략하게 나와있어서 좋은 방식으로 설명하기 어려워 gpt 에게 도움을 좀 받았습니다 )

다차원에서도 마찬가지로
기준점 xo 에서 x 까지 가는 경로 하나 잡고 계산하면
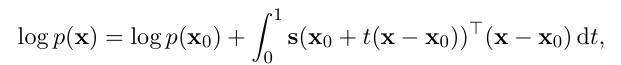
다음과 같은 수식이 나오게 됩니다.
- 경로 위에서 score 이 가리키는 방향 성분 계속 더하면 --> 최종적인 log p 의 높이 변화량을 얻을 수 있습니다.
3.1.3 Training EBMs via Score Matching
이전부터 계속 EBM 에서 MLE 가 어려운 이유를 뽑을때 z 가 intractable 하기 때문에 MLE 가 어렵다고 했었죠 ?
그리고 그걸 bypass 하기 위해서 스코어 ( 로그 미분 ) 형태로 보면 z 를 몰라도 괜찮었습니다.
이제 그러면 남은 문제가 어떻게 모델 스코어를 데이터 스코어에 맞출것인가 ? 에 대한 문제가 남아 있습니다.
어떻게 해결하는지 아래서 더 설명하겠습니다.
진짜 score 와 모델 score 를 맞추는 과정이 있어야 합니다(당연하게도). 따라서 수식은 아래와 같습니다.
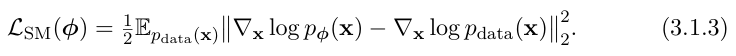
- log p_phi (x) : 학습할 score ( 모델이 제시하는 확률이 증가하는 방향장 )
- log p_data (x) : 데이터 분포의 score ( 진짜 데이터 분포의 확률이 증가하는 방향장 )
근데 여기서 문제가 p_data 를 모른다는것 입니다 ( 자연스럽게 log 취한 형식도 모르게 됨 . )
( 앞에 파트에서도 마찬가지로 p_data 는 사실상 저희가 구할 수 있는 형태였던적이 한번도 없었습니다. 이번에는 어떻게 우회하는지 잘 살펴보면 됩니다. )
그래서 이걸 어떻게 학습할지 이야기 하고자 합니다.
해결책 : 부분적으로 해결한다.
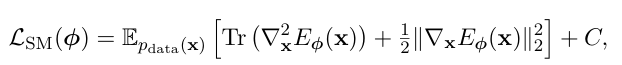
( Proof . )
D.2.1 ( appendix )
어떻게 해서 이 수식이 나오게 되었는지 따로 깊게 설명하고 있지는 않고 appendix 부분으로 빠져있는데 , 이부분도 공부 많이될거 같아서 가져왔습니다.
1) norm 수식을 전개한다.
기존 수식 L_sm 에서 제곱을 전개만 한 형태입니다 .

근데 마지막 E(s(x)) 는 상수취급 하니까 C 로 묶습니다.
그러면 사실상

이 두가지만 해결하면 됩니다.
2) 교차항 처리

수식을 다음과 같이 전개합니다. 좀 더 이해를 돕기 위해서 하나하나 풀어서 설명해볼까 합니다.
1. 기대값을 적분으로 쓴다.

s(x) 는 데이터 스코어 이고 기대값 정의에 따라서 수식을 만듭니다.
2. 데이터 스코어 정의
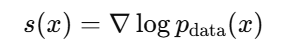
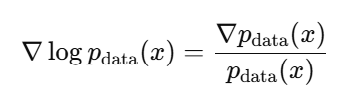
그냥 스코어의 정의를 가지고와서 다시 쓴 형태입니다.
3. 대입한다. ( p_data 가 약분된다 )
위에서 정의한 수식 그대로 다시 대입하면 다음과 같이 전개 되빈다.

그럼 여기서 p_data(x) 가 약분하는 형태가 됩니다. 그래서 맨 위 수식에서 두번째 줄 수식이 나오게 됩니다.
3) 성분별로 분해 ( 내적 -> 좌표합으로 )

이부분은 별거 없습니다. 그냥 성분대로 수식에 넣고 정리한겁니다.
그래서 최종적으로 맨 마지막줄의 수식처럼 정리됩니다.
< 핵심 : 부분적분 전개 >
이제 부분적분으로 마지막 수식을 전개합니다.
cf. Lemma ( 다변수 부분 적분 )-> 수능볼떄 많이 쓰는 그거 맞습니다 ( 그적 미적 .. 오랜만이네요 )

결국 저희 수식도 위와 똑같이 전개하면.

여기서 계항이 0이 되게 됩니다. 왜냐하면 증명에서 다음과 같은 가정을 두는데

이게 어떤 의미인지 좀 풀어서 설명을 해보면
현실적으로 데이터 분포가 보통 중앙 근처에 몰려있고 멀리갈수록 확률이 급격히 작아지는데 ( 이건 너무 자명한 이야기 )
그래서 R 을 점점 크게 보내면 p_data(R) 은 -> 0 에 수렴하게 됩니다.
따라서 위 수식이 0에 가까워지는 것이죠
그래서 결론적으로 뒤에있는 수식이 0이 됩니다.
자 다시 돌아와서 이제 경계항이 0이라는 것 까지 이해했으면 , 부분적분 결과 i = 1 .... d 를 합쳐서 다시 표현해야 합니다.

방금 위에서 부분적분 전개해서 얻은 식이 이거죠 ? 이걸 i = 1 ... D 를 다시 전부 합치기만 하면 됩니다.
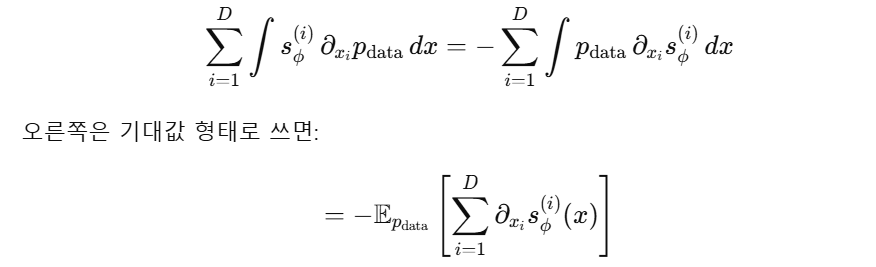
이떄 안에 수식이 Trace 이므로
( s(x) 는 D X D 야코비안이고 , 대각원소가 정확히 안에 수식과 같으니까 -> Trace 가 정확히 그 합이 되게 됩니다. )
따라서 수식이
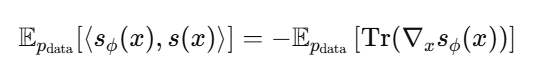
다음과 같이 정리됩니다.
이걸 다시 loss 식에 그대로 대입 하면


( 위쪽에 있는 수식에 대입만 하면 다음과 같은 수식이 됩니다. / C 는 아까 말했던 상수취급 )
증명 끗
자 그러면 이제 부분적분 에 대해서 증명은 마쳤으니 해당 식 의미부터 파악해보도록 하겠습니다.
Eϕ(x) : 해당 값이 낮을 수록 x 는 그럴듯한 데이터 ( 확률 높고 ) / 해당값이 높으면 그럴듯 하지 않다.
그래서 학습의 목표는 데이터가 자주 나오는 곳은 낮은 에너지로 만들고 , 데이터 주변은 높은 에너지로 만든다. 였습니다.
( 데이터가 있는 지점을 에너지 골짜기의 '가장 깊은 바닥'으로 만들어라 -> 이걸 2개라 나눠서 만든다고 생각하면 됩니다.
"가장 깊은" + " 바닥" 이런 식으로 말이죠 )
수식에서 항 2개가 있는데 하나씩 살펴보면
항1 ) : 1/2 || ∇ Eϕ(x) || ^2
∇ Eϕ(x) 는 지형의 경사인데
|| ∇ Eϕ(x) || ^2 이 크면 데이터 근처에서 지형이 매우 급경사라는 의미의미로
해당 항을 줄이면
- 데이터 주변에서 데이터가 너무 크게 요동치지 않게 만들고
- 결가적으로 모델이 내는 방향 ( 스코어 ) 도 안정적으로 된다.
-> 그래서 결론적으로 데이터가 있는 곳을 평평하게 만드는 역할을 하게 됩니다. ( 가장 깊은 )
항2 ) Tr( ∇^2 Eϕ(x) )
∇^2 Eϕ(x) 는 지형의 곡률인데 ( 얼마나 휘었는지 ? )
trace 가 그 곡률을 합친 값입니다.
- 데이터 근처 지형이 그냥 평평해지거나 이상하게 찌그러지는 걸 막고
- 골짜기 모양이 되도록 휘어짐을 맞추는 역할을 해준다.
-> 조금 더 직관적으로 설명하자면 , 앞 수식에 데이터가 존재하는 곳이 "평평" 하게 만들라고 수식을 정했었죠 ?
하지만 평평한 조건만 가지고는 해당 부분이 2차원 함수처럼 위로 볼록한지 아래로 볼록한지 알 수 없습니다.
그래서 이 수식이 "곡률" 을 조절하게 해주는데 스코어 매칭을 최소화 하는 과정에서 이항이
데이터 주위의 벡터들이 오목한 valley 로 만들게 해주는 것 입니다.
(바닥)
그래서 (가장깊은) + (바닥) 의 수식을 가지게 되는 것입니다.
참 이런걸 어떻게 생각했는지 대단한것 같습니다.
3.1.4 Langevin Sampling with Score Functions
저희가 지금까지 알아본 SCORES 는 데이터가 있을 확률을 가르키는 "방향" 에 대한 이야기였고
에너지가 낮을수록 P(X) 는 높고 ( 좋은 샘플이고 ) / 그 반대는 나쁜 샘플을 생성합니다.
그래서 샘플링은 아래 그림처럼 에너지를 낮추는 방향으로 X 를 움직이면 좋은 샘플이 나오게 될 것 입니다.

Discrete-Time Langevin Dynamics.
샘플링 수식은 다음과 같이 되는데
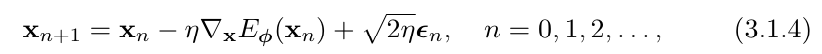

(1) −η∇E
- 에너지가 가장 빠르게 감소하는 방향을 의미합니다.
- 해당 xn 에서 다음 스탭으로 갈때 가장 빠르게 감소하는 방향로 가게 해 줍니다.
(2) +root(2η)ϵ
- 무작위로 흔들어주는 노이즈 역할을 합니다.
- 앞의 수식만 사용하면 local minia 에 갇히기 쉬운데 노이즈를 더해줘서 이 문제를 해결하고자 하였습니다.
-> 그렇다면 왜 노이즈 스케일이 root(2n) 인가 ?
- 가 작아지면 한 스텝 이동량이 줄어든다.
- 노이즈도 거기에 맞춰서 줄어야지 Continuous-Time 에서 깔끔하게 수렴한다 .
Continuous-Time Langevin Dynamics.
앞에서 본 수식에서 η를 “시간 간격" 이라고 보고 , 해당 간격을 매우 작게 쪼개면 SDE 확률 과정으로 수렴하게 되고
다음과 같은 형식이 되는데

다음과 같이 SDE 입니다.
( https://process-mining.tistory.com/207 - sde 에 관해서 참고 )
SDE 형태가 결국 두부분인데
1. 드리프트 : 결정적인 방향성 ( 우리는 여기서 스코어 )
2. 무작위한 변화 : Brownian motion 이라고 하는 무작위 노이즈 .
ODE 와는 다르게 SDE 는 같은 Xo 에서 시작해도 매번 실행할떄마다 결과가 조금씩 달라짐.
( Continuous-Time Langevin Dynamics ~ Inherent Challenges of Langevin Sampling. 보충 설명 필요 )
- 브라운 운동에 대해서 ( 참고 플로그 ) : https://seanlife.tistory.com/entry/%EB%B8%8C%EB%9D%BC%EC%9A%B4-%EC%9A%B4%EB%8F%99Brownian-motion-%EA%B3%B5%EA%B8%B0-%EC%A4%91-%EB%A8%BC%EC%A7%80%EC%97%90%EC%84%9C%EB%B6%80%ED%84%B0-%EC%A3%BC%EC%8B%9D%EA%B9%8C%EC%A7%80
3.2 From Energy-Based to Score-Based Generative Models
3.2.1 Training with Score Matching
다시 돌아와서 score는 다음과 같습니다.

- log p(x) 는 이 위치x 에서 얼마나 그럴듯한지 ( 높은 확률 밀도인지 ) 이고
- log p(x) 의 기울기는 어느 방향으로 움직이면 더 그럴듯한지 인지 알려주는 방향 화살표라고 보시면 됩니다.
앞서서 계속 이야기 했지만 , 결국 저희는 P_data 를 알 수 없기 떄문에 신경망으로 파라미터화된 벡터장으로 근사합니다.
( score s(x) 를 신경망으로 배우는 것이죠. )


score matching : 정답 socre 에 MSE 로 맞춘다.
사실 이게 가장 단순한 발상인데
MSE 로 아래와 같이 근사를 하고 싶은데 s(x) 를 모르기 때문에 계산을 할 수 없습니다.

그래서 다시 Tractable Score Matching 으로 넘깁니다.
앞서 증명했던 방식으로 정답 score 없는 형식으로 바꿉니다.
- S(X) 가 들어가는 항이 없고 ,
- sϕ와 데이터 샘플만으로 계산 가능한 형태로 바꿉니다.

Intuition of Equation (3.2.2).
1) magnitude 항 : 고밀도 영역을 stationary 로 만든다.
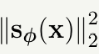
기대값이 x ~ p_data 에서 계산되므로 , 데이터 밀도가 큰 영역이 loss에 가장 크게 기여합니다.
따라서 이 항을 최소화 하면 해당영역에서 sϕ 가 0이 되도록 만듭니다. 따라서 고밀도 영역에서 벡터장이 0에 가까워지면서 움직이지않는 정지점 ( stationary ) 가 되도록 만듭니다.
하지만 이것만 조재한다면 stationary 가 안정적인지 불안정인지 결정이 안됩니다.
2) divergence 항 : stationary 를 끌어당기는 sink 로 만든다.

위 divergence 항이 음수면 sink ( = 정지점으로 모이는 것 ) 입니다. ( LOSS 이기 떄문에 작으면 작을수록 좋다 . )
( 반대로 0보다 크면 발산 . )
앞서 mangitude 항에서는 0이라서 멈추게 되지만 주변은 수축 ( 음수 ) 로 만드니까 근처 출발점들이 stationary 쪽으로 모여들게 됩니다. 따라서 stationary 지점이 멈춤 이 아니라 주변을 발아들이는 sink 가 됩니다.
3.2.2 Sampling with Langevin Dynamics
이제 저희가 가진 모델은 스코어 모델 = sϕ× (x)
- P_data(x) 에서 샘플을 뽑는게 목표였지만 그 자체는 알 수 없기때문에
- 스코어 ∇log p_data(x) 를 근사하는 sϕ× (x) 를 학습시켰습니다.

위 식은 한 스텝에서 세가지를 합쳐서 다음 위치로 가는 것입니다.
xn : 현재 위치
: 확률 높은 쪽으로 이동
- 스코어가 가리키는 방향으로 조금 이동 ( 앞 변수는 learning rate )
맨뒤 : 노이즈 ( 랜덤성 추가 )
- 그냥 스코어만 따라가면 다양성이 부족하기 때문에 노이즈를 추가해서 계속 흔들어주면 좀 더 잘 학습할 수 있다.
( 보다 조금 더 다양한 경로를 위함 . )
continuous version : SDE
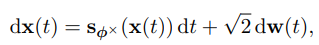
위 내용을 SDE 방식 (그니까 시간이 계속 흐른다고 보고 ) 적은 방식이다.
- 앞쪽 : 확률 높은 방향으로 움직이는 DRIFT
- 뒤쪽 : 무작위로 흔들리는 ( diffusion )
결국 SDE 를 컴퓨터에 그대로 못 돌리니까 시간 간격을 잘라서 근사하면 위의 Langevin update 가 나옵니다.
( SDE -> 작은 스텝으로 쪼개서 구현 == Langevin update )
3.3 Denoising Score Matching
3.3.1 Motivation
( 앞서 정의한 수식 )
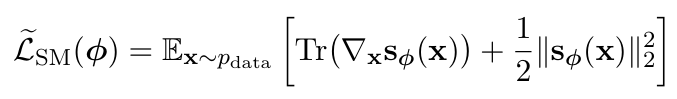
위 수식은 tractable 하지만 , 여전히 Jacobian Tr(s(X)) 를 계산해야하는 문제가 있습니다.
예를들어서 이미지면 보통 256 X 256 X 3 = 2,000,000 정도라고 가정하면 jacobian 은 200,00 x 200,000 행렬 이므로 원소만해도 어마어마합니다. 따라서 jacobian 을 만들어서 trace 를 구하는건 거의 불가능합니다.
또 , 대각선만 필요하니까 대각선만 계산하자 라고 해도 대각 원소 미분값들을 모두 구해야해서 구현상 D 번 수준의 미분/역전파가 들어갈 수 있고 최악의 경우 O(D^2) 까지 커질 수 있습니다.
Sliced Score Matching and Hutchinson’s Estimator
( 해당 부분에 대해서 좀 자세하게 서술했으나 , 네트워크 문제로 다 날라가서.. 일단은 이정도 서술 하도록 하겠습니다. )
계산하기 너무 어려우니까 적당한 u 를 뽑아서 몇개 샘플링의 평균으로 계산을 대체하자는게 해당 아이디어 입니다.
어떤 행렬 A 에 대해서 평균이 0이고 분산인 I 인 ( istropic ) 한 랜덤백터 u 가 있으면 수식이 다음과 같이 변하고
Tr(A) = E(uT A u )
sϕ(x) 쪽 역시 raom projection 으로 표현됩니다.
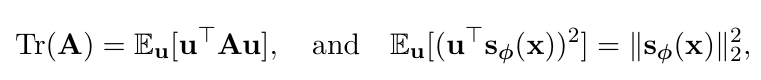

그래서 최종 수식이 다음과 같이 되는 것이죠.
짧게 요약하자면 이렇습니다.
1. D 차원 공간에서 전체 trace(발산) 을 알고싶다 ( 모든 축 방향 변화의 합 )
2. 하지만 계산이 너무 어렵다.
3. (ssm) 매번 랜덤 방향 u 를 뽑아서 X 에서 U 방향으로 slice 를 잘라 해당 slice 위에서 곡률/trace 를 측정
4. 여러 u 를 평균냄.
이전 작성하던게 사라져서 대신에 (글씨가 더럽지만 )
개인적으로 공부한 부분 첨부합니다.

직접한번 2차원두고 작성해보니 이해가 더 잘되더라구요.
jvp/vjp 로 행렬없이 uT J u 를 구할 수 있어서 계산이 빨라진다고 합니다.
From Sliced to Denoising Score Matching
Sliced Score Matching은 복잡한 수학 계산(Jacobian)을 피하려고 만든 기법입니다. 하지만 다음과 같은 치명적인 단점이 있습니다.
- 매니폴드(Manifold) 가설의 함정: 고해상도 이미지 데이터는 사실 광활한 공간 전체에 퍼져 있지 않고, 아주 얇고 구부러진 특정 영역(저차원 매니폴드)에만 밀집해 있습니다. 데이터가 없는 구역에서는 "어느 방향이 데이터가 있는 방향인지" 가르쳐주는 수치(log p_{data}(x)) 자체가 정의되지 않거나 매우 불안정합니다.
- 좁은 시야: 실제 데이터가 있는 '점' 위에서만 학습이 이루어지다 보니, 그 점을 조금만 벗어나도 모델이 길을 잃어버립니다. (주변 동네에 대한 정보가 부족함)
- 계산 효율과 노이즈: 매번 계산할 때마다 방향을 무작위로 정해 확인해야 하므로(Probe-induced variance), 결과가 들쑥날쑥하고 반복적인 계산 비용이 큽니다.
따라서 이런문제점을 보안하고자 DSM(Denoising Score Matching) 라는 방식을 제안합니다.
DSM 의 아이디어
원본 데이터 x 를 그대로 쓰지 않고 노이즈를 섞은 데이터를 가지고 score 를 학습한다.
- 공간 전체로 정보가 확장된다. : 점으로 존재하던 데이터가 노이즈로 인해서 주변으로 버지는 효과가 생긴다.
- 명확한 정답 제거 : 저희가 noise 를 투입한 것이기 때문에 노이즈의 양을 알고 있습니다. 따라서 노이즈 섞인 데이터를 원래 데이터 로 되돌리면 어느 방향으로 가야하는지를 학습 목표로 세울 수 있습니다.
3.3.2 Training
이 챕터에서는 DSM 이 intractable 한 p_data(x) 없이도 score 를 학습할 수 있는가에 대해서 정리한 챕터입니다.
자세하게 알아보도록 하겠습니다.
먼저 원래 목표를 revisit 해보겠습니다. 원래 계산하고 싶던 수식은 다음과 같았죠?

하지만 여기서 p_data(x) 를 알 수 없었고 , 저희는 샘플 x 만 있고 당연하게도 p_data 밀도 함수 자체가 없기 때문에
trace 형태의 score matching 으로 바꿨었고 ( SSM 은 ) 거기서 trace 를 hutchinson 으로 처리했습니다.
Vincent (2011)’s Solution by Conditioning
2011 년에 나온 아이디어라니 참 신기합니다 (얼마나 앞서간거야.. )
해당 아이디어를 정리하자면 다음과 같습니다
- 노이즈를 섞으면 score 가 계산 가능한 조건부가 생긴다. ( 위에서 이야기 했던것과 유사합니다. )
1. 데이터에 노이즈를 섞습니다
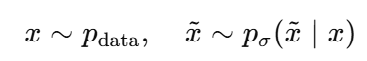
여기서 오른쪽 p() 는 직접 설계한 ( known 분포 ) 입니다. ( 가지고 있는 데이터 x 에 직접 noise 를 추가했기 떄문 )
이렇게 하면 노이즈가 섞인 샘플 의 marginal 분포가 생깁니다.

이식은 p_data 를 gaussian 으로 convolution 한 smooting 분포라고 생각하면 됩니다.
수식에 대한 조금 더 친절한 이해
위 수식은 그냥 노이즈 섞은 결과의 전체 분포를 쓰는 수식입니다.
x~p_data : 원본 데이터에서 하나 뽑음
x~ ∼ pσ(x~∣x) : 그 x 에 노이즈를 섞어서 x~ 를 만듦 ( 노이즈 이미지 )
결국 노이즈 이미지 x~ 는 어떤 x 에서 왔는지 모르기 때문에 ( 학습할떄는 pair 로 알고 있지만 , x~ 만 보고 원본이 뭐였는지는 알 수 없음 )
따라서 x~ 의 분포 p(x~) 는 가능한 원본 x 에 대해
x 가 나올확률 x ( 그 x 에서 x~ 로 노이즈가 만들어질 확률) 를 다합친 값입니다. ( 이게 해당 위의 적분 식 )
2. 모델의 목표를 바꿉니다.
이제 모델이 clean x 가 아니라 noisy x~ 에서 score 를 맞추도록 합니다.

아직 문제가 있는데
∇logpσ(x~) 는 marignal score 라서 일반적으로 intractable 한 문제를 conditioning trick 을 사용해서 이를 해결합니다.
좀더 쉽게 이야기하면 결국 p(x~) 수식 역시 적분으로 정의된 분포라서 lot p(x~) 와 해당 기울기도 보통 계산이 어려운 단점이 있습니다.
Conditioning Trick
위의 3.3.1 수식에서는 x 를 같이 알면 계산이 쉬워지는 것을 이용합니다.
( 이전 diffusion 에서도 마찬가지로 원본 x 를 알고있다고 가정한 수식으로 인해서 엄청 계산이 편리해졌습니다. 여기서도 마찬가지 트릭을 이용해서 해결합니다. )
DSM loss ( Denoising Score Matching loss ) :

여기서는 조건부 수식으로 바뀌는데
- 학습할때 원본 데이터 x 를 샘플로 가지고 있고
- 노이즈를 우리가 직접 섞어서 x~ 를 만들었고
- 그러면 p(x~|x) 는 직접 정한 노이즈 모델이라서 수식이 매우 명확하기 때문에 lot p(x~|x ) 역시 closed form 으로 계산이 가능해집니다.
수식에 대해서 조금 더 자세한 설명을 해보자면..
1) MSE regression 의 최적해 = 조건부 기대값.
타겟을

위처럼 두면 ( loss 수식에서 뒷부분 )
그러면 DSM 이
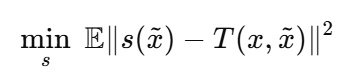
해당 문제를 푸는 것과 마찬가지인데
우리는 X~ 는 고정이고 ( 노이즈가 추가된 X 가 입력값이니까 )
T(x,x~) 가 랜덤이므로
( DSM 은 사실상 X~ 를 입력으로 받았을때 X 에 의해 바뀌는 조건부 SCORE 의 평균으로 제일 잘 맞추는 함수를 찾는 문제로 보면 된다. )
( 이해가 잘 안갈 수 있지만 , 입력 x~ 는 같을 수 있어도 ( 노이즈이니까 ) 원본 x 에 따라서 타겟이 달라지게 된다. )
( 완전 noise -> 강아지 or 고양이 일 수 있기 떄문. - 이건 x (원본이미지) 에 전적으로 달려있다. )
( MSE 에서는 결국 최적의 해는 조건부 기대값이므로 ( 그래야 LOSS 가 제일 작다 ) 아래와 같은 수식 전개가 되는 것이다. )
MSE regression 에서 최적 예측값은 조건부 기대값이므로 , 따라서 최적해는 다음과 같다.

근데 사실상 수식이 다음과 같으므로.

DSM 을 최소화하면 결과적으로
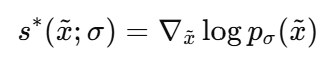
다음과 같다.
이게 책에서 이야기하는 (3.3.2) 의 optimal minizier 가 (3.3.1)의 optimal minimzer 와 같다는 말이다.
결론 : DSM 의 최적해는 noisy marginal score 이다.
2) 가우시안 노이즈면 closed form 이라 tractable 이다.
아까 위에서 cloased form 이라 tractable 하다고 하고 넘어 갔는데 조금 더 자세히 살펴보겠습니다.
( 책에서 special case : Additive Gaussian Noise 부분을 여기서 설명하겠습니다. - 구조상 이게 더 이쁜거같아요 )
( 노이즈 주입 정의 )
- x∼pdata
- ϵ∼N(0,I)
- x~=x+σϵ
다음과 같이 정의되고 이러면 조건부 분포가 다음과 같이 된다.

( x 를 중심으로 분산 σ^2 짜리 gaussian 뿌려서 x~ 만듬 )
그림으로 보면 아래와 같을것이구요.

왼쪽 log p_data (x) : 직접 계산이 불가능하고
오른쪽 score log p(x~|x) : 계산이 가능해집니다.
그래서 조건부 score 가 다음과 같이 나오게 됩니다.

증명.
통계학이 가물가물하네요
Gaussian PDF
https://gaussian37.github.io/math-pb-about_gaussian/
가우시안 pdf 밀도는

아래와 다음과 같고 이걸 우리 case 에 대입해보면 ..
Σ=σ^2 I 이므로 ( 아래와 같은 수식이였으니까 )

이걸 대입해서 정리하면.. ( 여차여차 정리하시면 )
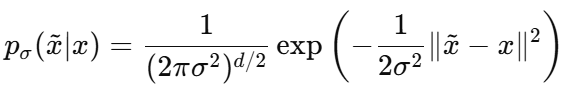
다음과 같이 됩니다.
여기서 log 씌워주고 미분하면 담과 같이 정리됩니다.

직관적으로 x~ 가 x 에서 멀어질수록 원본 x 쪽으로 끌어당기는 힘이 세지고 , 분산이 크면 그 힘이 약해지는 형태를 띄게 됩니다.
( 그래서 DMS loss 가 어떻게 단순해지는지 ? )
위에서 정의한 수식을 DSM 에 그대로 대입하면 다음과 같이 됩니다.
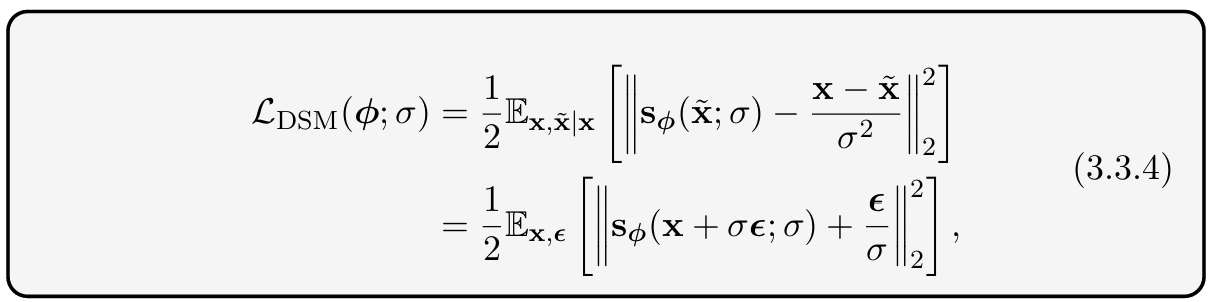
첫번째줄 s( ) 에서 x~=x+σϵ 치환하면 아래 수식이 되게 됩니다.
해당 수식이 왜 denosing 인지 / σ 크거나 작으면 무슨일이 일어나는지 , 그래서 종합적으로 왜 생성이 가능한지 더 서술합니다.
1) σ가 작으면 pσ와 pdata의 high-density region & score가 거의 같다

원래 수식이 다음과 같습니다. 데이터 분포를 가우시안으로 블러링한 분포죠.
근데 여기서 σ 가 작으면 -> 블러가 거의 없고 -> 분포 모양도 이전 스텝과 거의 같겠죠 ?
그래서 확률이 큰 영역도 거의 그대로 일 것이고 , 따라서 score 도 거의 비슷할 것 입니다. 따라서..

( 이미지에 가우시안 블러를 약하게 먹이면 원본이랑 거의 같으니까 , 분포도 동일하게 아주 살짝 뭉개진 정도일 것이다. )
2) noisy score 방향으로 한 스텝 가면 clean 분포의 고확률 영역으로 간다
한 스텝이라고 하면

확률이 커지는 방향으로 움직일텐데
score = log 확률의 증가 방향
그래서 score 방향으로 조금 움직이면 p(x~) 가 커지는 쪽으로 가게 됩니다.
- 다시 아까 위에서 σ 가 작으면 pσ 아 p_data 가 거의 유사하다고 했으니까 --> 결국 데이터가 같은 쪽으로 가게 됩니다.
3) 그래서 이걸 왜 denoising 이라고 부르나 ?
아까 3.3.4 에서 가우시안 조건부 score 수식이 다음과 같았으므로.

위 수식은 x~ 를 x 로 되돌리는 방향을 의미하므로 !
Tweeie 공식을 이용해서 denoising 과 score 를 직접 연결하는데
--> 이후 더 자세한 설명은 뒤에서 추가로 하니 여기서 마무리 짓고 넘어가겠습니다.
+) σ가 크면 왜 over-smooth(평균으로 수축)하나?
σ가 크면 pσ가 엄청 블러한 분포일텐데
-> 이러면 모든 디테일이 섞여서 사라지고 분포가 큰 구름 하나처러 ㅁ되어서
-> score 마찬가지로 디테일한 모드가 아니라 그냥 전체 질량이 큰 대충 평균 중심으로 끌어당기는 벡터가 되어서
denoising 을 하더라도
-> 디테일이 살아나는게 아니라 coarse 한 denoising 이 되어서 over smooth 가 발생한다.
좋습니다. 조금 논의가 길어졌지만 다시 돌아와서. 정리해보면

- 원래 L_SM ( 노이즈가 들어간 분포의 정답 score 를 맞추는 MSE ) 는 정답 socre log p(x~) 떄문에 직접 계산이 어려워서
- L_DSM ( denosing score matching ) 으로 바꾸면 정답 score 를 조건부의 닫힌형으로 바꿔서 학습할 수 있고 , 놀랍게 두손실은 ϕ 에 대해 동일한 최적해를 갖게 됩니다.
( 4장에서 더 자세히 다루므로 이정도 다루고 가겠습니다 . )

쉽게 설명하자면
- 원래 목표가 marginal 이라서 계산이 어려운걸 , 원본 데이터 x 에 조건 (condition) 을 걸어 conditional 로 바꿔서 Monte Carlo 로 추정을 할 수 있게 합니다.
- 그리고 그 조건부 목표를 평균내면 다시 원래 marginal 목표와 연결되게 됩니다.
이게 DDPM 과 Flow matching 에서도 똑같은 패턴이 발생합니다. 간략하게 작성해보면
1) DSM 에서 condition

정답이 closed form 이라서 샘플 (x , x~ ) 만 있으면 MSE를 몬테 카를로로 바로 학습 가능하게 되고
2) ddpm 에서 conditioning
DDPM 에서 보통 ELBO 를 최대화 하는 형태인데 , 이걸 직접 다루려면 어렵기 떄문에
forward : ( 여기는 직접 x 에서 샘플링 하기떄문에 쉽고 )
backward : 여기서도 xo 를 conditioning 으로 쓰면 closed form 으로 계산가능합니다.
( 이부분은 2장 참고 하시면 됩니다.)
읽으면서도 뭔가 직관적으로 이런 부분이 score 랑 비슷하겠구나 .. 싶었는데 책에서 정리해주네요 . 뭔가 뿌듯합니다.
아무튼 이런식으로 tractable 하게 만들어줍니다.
3) flow matching
요즘 FLUX 나 QWEN 같은 프론티어 모델들도 보통 flow 를 많이 쓰는데요 . 역시 마찬가지로 비슷합니다.
이부분은 flow matching 때 다시 보는걸로 하겠습니다.
3.3.3 Sampling
샘플링 관련해서 이야기 해보겠습니다.
학습된 스코어 모델이 있따면 , 이걸 이용해서 실제 데이터와 유사한 샘플을 만들 수 있는데 , 이때 사용하는 방법이 langevin dynamics 입니다.
- 무작위 초기값 Xo 에서 시작해서 , score 를 따라서 조금 씩 이동하면서 한 스탭마다 noise 를 추가해서 coverage 개선을 할 뿐만 아니라 공간 전체에 데이터를 퍼지게 하는 효과를 줄 수 있습니다. ( 실제 데이터는 전체 공간에 비해서 매우 좁은 영역에만 몰려 있기 떄문. )

수식은 다음과 같은데
S() : 드리프트 항 ( 확률이 높은 곳으로 끌어가는 항 )
노이즈 항 : 한 모드에 갇히지 않고 주변을 탐색하는 효과를 주게 합니다.
Advantages of Noise Injection.
1. Well-defined gradients
실제 데이터 분포 p_data 는 매우 얇은 manifold 근처에 몰려있다. ( 전체 공간 D 에 퍼져있지 않고 대부분 아주 얇은 층 위에 존재한다 . )
이런 경우 log p_data(x) 를 전체 D 차원에서 정의하기가 어렵고 학습이 잘 되지 않는다.
하지만 gaussian convolution 을 한 pσ ( = p_data * N(0,σ2I) ) 는 훨씬 더 매끈하고 score 를 잘 정의할 수 있다.
-> 데이터 분포에 두께를 줘서 , score 공간 전체에서 보다 더 안정적으로 정의할 수 있게 해준다.
2. Improved converage
데이터 분포는 여러 모드가 있고 ( 모드 = 클러스터 ? ) , 그 사이가 거의 밀도가 0인 경우가 많다.
근데 문제가 있는데 해당 사이 밀도가 0 인 경우에 ( score 가 거의 없거나 불안정 ) 하기 떄문에 샘플이 한 모드에 갇혀서 다른 모드로 못넘어간다.
노이즈를 섞어서 보다 조금 더 블러링하게 되면 모드 간의 연결을 조금이라도 더 증가시킬 수 있다.
대략 시각적으로 보면 이렇다.

3.3.4 Why DSM is Denoising: Tweedie’s Formula
일단 다시 정리를 좀 해보자.
실제로 하는 일
원인 : 이미지 x ( 수많은 고양이 사진 중 하나 )
결과 : 노이즈가 섞여 나온 x~ ( x 에 가우시안 노이즈가 더해진 결과물 )
그런데 x~ 는 정해진 하나의 x 에서 나오는게 아니라 p_data(X) 전체에서 x 가 뽑히고, 거기에 노이즈가 더해져서 만든 랜덤 결과이다. 따라서 우리는 x~ 를 보고 원본 x 를 찾아야 하는게 원래 목표였는데 , x~ 만 보고 x 를 하나로 정해지지 않으므로
수학적으로 가장 확률 높은 원인의 평균을 구하는 것이 최선일 것이다.
( 결국 이를 잘 정의해야 loss 를 정의할 수 있기 때문에 .. )
글을 한번에 읽고 작성하는게 아니다 보니 이쯤오면 기억이 안나는 부분이 있어서 리마인드를 한번 하고 갈까 한다.
1. 우리가 아는건 한가지 정보이다.


꺠끗한 X 에 NOISE 를 추가해서 X~ 를 만들었다는 것.
즉, X 가 주어지면 X~ 는 평균 ax 인 가우시안에서 나오게 된다는 의미이다.
2. 이 가우시안 score ( log 밀도 기울기 ) 를 직접 계산한다.
score :

이걸 이제 계산해보면 ..

다음과 같다. 여기서 x~ 로 미분하고 적절히 계산하면 .

이렇게 되면 항상 x~ 를 ax 쪽으로 끌어당기는 방향이다 ( 이게 score )
자 그래서 여기서 x 를 우리는 모르기 때문에 ( x~ 만 보니까 ) x~ 를 봤을떄 x 가 뭘지에 대한 분포 (posterior ) 는 존재한다.

( 위 수식이 우리가 이전 설명으로 인해서 알 수 있던 분포이고 ) 그래서 위 식을 평균을 낸다.

해당 수식을 다시 정리해서 보면 .

다음과 같이 정리된다.
여기서 가장 핵심적인 부분이 나온다.
" DSM이 score ∇x~logpσ(x~)를 배우면, 그걸로 “최적 디노이즈(=posterior 평균)”를 바로 만들 수 있다. "

수식으로 바꾸면 다음과 같다.
관측 x~ 가 에 대한 marginal p(x~) 의 score ( 기울기) 는 x~ 를 만든 원인 x 가 무엇인지에 대해서 posterior 평균낸 조건부 기울기와 같다고 주장한다. ( 실제로 수식적으로도 증명한다. )
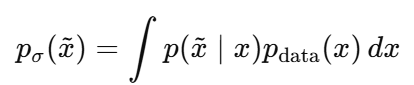
아래에서 p (x~) 정의를 보면 다음과 같은데 , 처음부터 원인 x 를 적분해서 만든 분포이므로 , x~ 기울기를 구할떄에도 내부에 들어있는 p(x~|x ) 의 기울기가 x에 대한 posterior 로 평균되어 나오는게 꽤나 그럴 듯 하다
( 증명을 여기서 따로 하지는 않겠다. )
< 이부분 조금 더 설명하기 >

3.4 Multi-Noise Levels of Denoising Score Matching (NCSN)
3.4.1 Motivation
먼저 이번 섹션 (3.4) 에서는 왜 노이즈를 한번만 넣어서 DSM 를 학습하면 샘플링이 어렵고 , 품질의 한계가 생기는지 설명하고 -> 그래서 여러 노이즈 레벨을 동시에 학습하고 , 샘플링떄는 큰 노이즈 -> 작은 노이즈로 점점 줄여가야 하는지에 대해서 서술한다.
1) 단일 DSM의 구조 및 한계
DSM 은 이전에서 설명했던 것과 비슷하게
- 데이터 X ~ P_data
- 노이즈 주입
- 네트워크가 noise 추가된 분포의 score 를 맞추도록 학습 한다.
근데 이떄 한개의 σ 만 사용하면 샘플링이 힘들어진다.
(A) σ 가 너무 작은 경우
- P_ σ 와 P_data 가 너무 비슷해진다. ( 이렇게 되면 원래 데이터 분포는 보통 mode 사이에 밀도가 매우 낮은데 이렇게 되면 mode 사이의 영역에서는 사실상 샘플링이 불가능하게 된다. / 이전에 설명했던 단점이 또 나오는 것이다. )
- 따라서 저밀도 구간에서는 gradinet 가 약하거나 틀릴 수 있어서 다른 mode 로 넘어가기 매우 어렵게 된다.
(B) σ 가 너무큰 경우
- 분포가 너무 smoothing 된다. 이러면 대략적인 구조는 맞출 수 있는데 세부 디테일이 뭉개져 버린다.
- 여기서 학습만 하면 샘플이 큰 형태만 맞는 블러리 샘플로 나오게 된다.
정리하면
- 작은 σ: 디테일은 가능하지만 탐색/모드 이동이 어려움
- 큰 σ: 탐색은 쉽지만 디테일 회복 불가
→ 하나의 σ로는 둘을 동시에 잡기 힘듦 - 따라서 다양한 noise 를 사용하자 !
cf .
그래서 논문에 나와있는 그림을 빌려서 다시 설명을 좀 해보자면.


검은 화살표 : 학습된 score
파란 화살표 : 정답 score
여기서 핵심은 저밀도 영역에서 검은 화살표와 파란 화살표의 방향이 차이가 많이 어긋난다는 것이다. ( 둘이 겹치는 부분이 노란색 위주로 있고 , 멀어질수록 차이가 나는걸 확인할 수 있다. )
그래서 그림을 보면
노란색 구역 ( high density ) : 여기서는 실제 데이터 p_data 가 밀집되어 있는 구역이라서 , 해당 구간에서는 score 가 더 정확하다.
빨간색 구역 ( low density ) : 데이터가 거의 존재하지 않는 빈 공간이다. 모델이 이 구역의 데이터는 거의 본 적이 없기 때문에 문제가 생기는 구간이다.
NCSN
그래서 Noise 를 여러 단계로 바꿔가면서 , 각 단계에서 지금 이 노이즈 수준에서 데이터가 더 좋은 방향 (score ) 로 알려주는 신경망을 학습하고 , 생성할때는 noise 를 큰단계 -> 작은 단계로 내려오면서 점점 디테일을 복원하는 방식입니다.
( 다른 논문들이나 생성 모델도 보통 coarse 를 먼저 잡고 그다음에 fine 을 잡는 형식으로 생성하는걸 확인했었습니다 )
아까
- 작은 σ: 디테일은 가능하지만 탐색/모드 이동이 어려움
- 큰 σ: 탐색은 쉽지만 디테일 회복 불가
라고 설명했는데
노이즈가 큰 경우에는 데이터가 있는 방향 자체는 대략적으로 알 수 있고
노이즈가 작은 경우에는 디테일한 정보들을 표현할 수 있음을 알았습니다. 따라서 이를 이용해서 구성합니다.

여기서 x 는 원본 이미지 샘플이고
xi 는 x 에 노이즈를 섞어서 만든 샘플입니다.
( forward )
위쪽 검은 화살표가 p_σ(xσ∣x) 를 나타내는데 원본 x 로부터 각각 따로 샘플링 (x1 .... xL ) 합니다.
forward 는 시간에 따라 x -> x1 -> .... -> xL 을 실제로 연쇄적으로 변환한다기 보다 각 노이즈 레벨별로 직접 생성합니다.
(Reverse )
회색 점선 화살표가 생성(샘플링) 인데, 큰 noise 에서 작은 noise 로 진행되게 됩니다.
이렇게 하면 위에서 말했듯이 큰 noise 부분에서는 밀도가 낮은 곳에서도 샘플링할 대략적인 위치를 알 수 있게 됩니다.
(langevin)
각 단계마다 Langvein 을 여러번 반복하게 됩니다.
노이즈 레벨 i 를 고정한채 , langevin 업데이트를 여러 스텝 반복하게 됩니다.
여기서 여러스텝을 한 구간에서 밟는 이유는 한 번 업데이트로는 분포에서 샘플링이 잘 되지 않고 ( 여러번 돌려도 결국 분포가 수렴하도록 설계되어 있고.. ) 여러번 반복해서 목표 분포 근처로 가도록 해야합니다.
이부분은 뒤에서 조금 더 자세히 설명하겠습니다.
그래서 대략적인 청사진은 다음과 같고 이제 각 부분을 조금 더 디테일하게 알아보도록 하겠습니다. ( 수식을 곁들인 )
3.4.2 Training
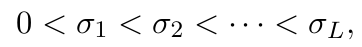
계속이야기 했듯이 noise 의 크기를 다양하게 가져간다.

다음과같이 원본 분포의 score 가 아니라 가우시안으로 스무딩된 여러 버전의 p 들의 score 를 전부 학습해서 큰 noise 에서부터 작은 noise 를 단계적으로 갖출 수 있게 한다.
Training Objective of NCSN

전체 L_ncsn loss 는 위와 같습니다.
L개의 다양한 noise 에 대해서 각각 DSM loss 를 구한뒤에 , 이를 모두 한번에 더해서 한꺼번에 학습시킵니다.
이때 각 가중치 ( = 각 노이즈 레벨별로 얼마나 중요하게 다룰지 결정 ) 까지 곱한뒤 더해서 총 los s를 구하게 됩니다.
아래 수식은 DSM loss 한개 ( noise levl 고정 ) 을 한 수식입니다. 이건 앞에서 많이 이야기했으니 자세한 설명은 패스하겠습니다.
( 앞선 설명 3.3.1 참조 )

결국 DSM 최소화 => 진짜 score 복원과 같은 의미이므로. ( 3.3.1 참고 )
x~ 가 주어졌을때 원래 x 가 어디였을지 posterior 평균 방향으로 끌어당기는벡터가 , 바로 x~ 분포에서 확률이 커지는 방향을 score 라고 이해하고 넘어가심됩니다.
Relationship with DDPM Loss
앞에서 했던 이야기 다시 리마인드 정도입니다.
score 랑 DDPM 이 어떻게 같은지에 대한 서술입니다.

좌변 : score
우변 : noise x 가 주어졌을때 노이즈가 평균적으로 얼마나 섞였는지 조건부 평균 스케일링
-> 노이즈 평균 알면 score 알 수 있다.
앞서 이야기 했던 Tweedie 때문에 ( 최적 score = DDPM denoise )

둘이 파라미터 ( 대략 여기서는 스케일 ) 만 다르지 결국 동일한 함수 정보를 가진다.
( 더 자세한 이야기는 ch 6 에서 다룬다 )
3.4.3 Samplining
다음 알고리즘 1 은 SCORE 가 있을때 샘플링 하는 방식을알려준다. ( ncsn 식 샘플링 )

큰 노이즈 (L) 부터 시작해서 각 노이즈 레벨에서 Langevin 을 Nt 번 반복한 뒤
나온 결과물을 더 작은 노이즈 레벨의 초기값으로 넘긴다.
조금 더 자세히 살펴보고자 한다.
큰 노이즈에서 작은 노이즈로 내려가면서 복원 ( coarse -> fine )

( 각 noise level 마다 langevin dynamics 실행 )
langevin 업데이트 수식을 보면 두번째 수식은 score 가 확률이 커지는 방향으로 가지고 가고 , 세번째는 noise 를 추가하는 항 입니다.

그래서 MCMC 로 p_i 에서 샘플링하려는 업데이트이고
step size 같은 경우는 다음과 같이 스케일링 합니다.

노이즈가 큰 레벨은 좀 거칠고 안전한 반면 , 작은 레벨은 예민하기 때문에
- 큰 노이즈 에서는 smoothing 분포라서 score 필드가 덜 sharp 하고 조금 움직여서 필드가 안 꺠지는 반면
- 작은 노이즈에서는 p 가 원본 분포에 가까워져 sharp 하게 딘다.
따라서 작은 noise step 에서는 step 을 더 작게 잡아야 한다.
Slow Sampling Speed of NCSN.
NCSN 은 당연하게도 구조적으로 엄청 느립니다.
1. 샘플링이 MCMC 라서 K 번 반복이 필요하다.
2. 노이즈 레벨이 여러개이므로 더 오래 걸린다.
3. 게다가 병렬화도 안된다 ( 더 큰 NOISE 쪽의 OUTPUT 이 나와야 그다음을 돌릴 수 있다 )
Summary : A Comparative View of NCSN and DDPM
NCSN 과 DDPM 의 공통점과 차이점을 한번 정리하고 가려고 합니다.
공통점
- Forward : 원본 x 에서 noise 를 추가한다.
- Reverse : noise 에서 시작해서 x 로 돌아온다.
차이
NCSN : 각 노이즈 레벨에서 score ( log p(x) ) 를 직접 근사해서 Langevin dynamics 로 샘플링한다.
DDPM : reverse trasition p(x_i-1 | x i ) 를 모델링 ( 그니까 noise 예측 ) 을 통해서 Markov chain 으로 한 스텝씩 뒤로 되돌린다.
아래 Table 3.1 을 보면 더 정리가 직관적으로 된다.

1. 첫번째 줄 ( x i+1 | x i )
DDPM 쪽은 Forward 시 markov chain 으로 정의하는 걸 볼 수 있습니다.
그래서 매스텝마다 가우시안 노이즈를 섞고
beta 스케줄이 얼마나 노이즈를 넣을지 정하게 됩니다.
NCSN
ncsn 에서는 노이즈 레벨 별로 두고 ( σi )
( xi = x + σi ϵ )
각 레벨에서의 pertubed distribution 정의 한 뒤에 적절히 유도하면 맨 첫번째 수식이 나오게 됩니다. ( 유도과정은 앞쪽에 있으니 생략할께요 )
2. 두번쨰 ( xi | x )
원본 x 에서 xi 가 어떻게 생기는지
- 여기서는 사실상 동일한 형태로 만들게 됩니다.
xi = (scale) * x + (noise scale ) * ϵ
와 같은 형태를 가지게 됩니다.
3. prior
NCSN : 가장 큰 노이즈 레벨 ( L )
DDPM : 순수한 NOISE
- 둘다 거의 순수한 노이즈에서 시작된다고 보면 됩니다.
4. Loss
이부분은 앞에서 많이 설명해서 수식적인 설명은 생략하고 결론만 이야기 해보자면
NCSN 과 DDPM 둘을 수식 전개를 해보면 결국 가우시안에서 score 와 노이즈는 선형변환관계와 유사하게 됩니다.
따라서 score 맞추는것과 노이즈 맞추는게 표현만 다르고 거의 본질적으로 비슷하게 되는 것 이죠
5. Sampling
NCSN : 각 레벨에서 Langevin 을 여러번 돌리면서 업데이트를 하고
DDPM : reverse Markov chain 을 한 스텝씩 합니다.
< A shared Bottleneck >
DDPM & NCSN 둘다 time / noise 축을 매우 많이 돌려야 성능이 나와서 , 샘플링 시 매우 많은 step 을 거쳐야 해서 느립니다.
( 제가 알기로 DDPM 의 경우 1000 step 정도였던 것 같습니다 )
( 이부분에 대한 해결 방안은 ch 9 / 10 에서 설명한다고 합니다 )
3.6 Closing Remarks
최종 서머리 하고 마무리 하도록 하겠습니다
1. EBM
- EBM 은 데이터의 확률 분포를 학습할 수 있는 방식이지만 , tractable 한 문제가 있었습니다. ( z 라는 정규화 상수 때문에 )
- 로그를 취한뒤 미분을 통한 Score function 을 이용해서 이 문제를 우회했습니다.
2. score -> DSM
- 기존 score matching 은 모델 score 가 데이터 score 를 맞추는 형식이지만 p_data 를 직접 계산할 수 없는 단점이 있어서
- DSM 에서는 p_data 분포에 노이즈를 넣어 x~ 를 만들고 , x~ 의 분포 p(x~) 의 score 를 학습시킵니다.
3. Tweedie formula
- score = denoise 라는 것을 수식적으로 증명하면서 score & denoising 을 묶어주는 역할을 합니다.
4. NCSN & Diffusion
- NCSN 과 DDPM 이 결국 유사한 구조를 가지게 됨을 배웠습니다.
TODO :
결국 DDPM 과 NCSN 의 모델이 수렴이 우연이 아니고 , 더 깊은 수학적인 구조를 암시한다고 말합니다.
이 더 깊은 구조가 score SDE 프레임 워크이고 이는 챕터에서 더 깊게 배워보도록 하겠습니다.
- 소감 :
score 쪽 이해도 괜찮았고 NCSN 자체도 큰 문제는 없었는데 Tweedie 나오면서 이해가 살짝 무너졌다.
계속 일이 너무 바쁘고 야근을 해서 시간이 없다보니까 이산적으로 공부해서 끊기면서 살짝 정리도 아쉽고 이해도 아쉬운데 , 시간날때마다 보면서 글 리팩토링을 좀 진행해야겠다.
헷갈린 점들
- training vs sampling 에서 noise 항의 필요성에 대해서 . (sampling 할때는 왜 필요한 것인가 ? )
이게 한번에 읽은것이 아니다 보니까 좀 이해가 끊겨있다. 그러다보니까 전체 그림을 살짝 못그려서 중간에 헷갈렸다.
이부분은 gpt 를 이용해서 이해를 보강해보는 것을 추천.
- DDPM 와 SCORE 의 연결성 ( 수식적으로 )
참고사항
- vector field 의 divergence https://angeloyeo.github.io/2019/08/25/divergence.html
- trace
- ( 혼자 생각하다가 의문이들어서 ) : 그러면 diffusion 으로 학습시키고 score처럼 샘플링해도 되는거 아닌가 ? -> 여기에 대한 해답은 DDIM 에 있다. DDIM 을 확인하면 내 의문 처럼 diffusion 으로 학습시키고 Score 처럼 샘플링한다. ( 10~100 배정도 샘플링이 빠르고 퀄리티가 좋다고 한다 )
'The Principle of Diffusion' 카테고리의 다른 글
| [The Principles of Diffusion Models] 이해하기 - ( Part B ) CH 2. DDPM (with VAE ) (0) | 2025.12.07 |
|---|---|
| [The Principles of Diffusion Models] 이해하기 - ( Part B ) CH 2. VAE (1) | 2025.11.19 |
| [The Principles of Diffusion Models] ( Part A ) (0) | 2025.11.03 |