
summary
우리가 일반적으로 사용하는 CNN의 경우 local 한 특성 만을 볼 수 있는 구조입니다. receptive field 크기의 관점에서 보면 local operator를 여러차례 쌓으면 receptive field의 크기를 키울 수는 있지만 아무리 많이 쌓더라도 한 번에 전체 영역을 살펴보는 non-local operator와 같을 수는 없습니다. 그렇기에 저자의 주장으로, 이런 non-local operator가 long range dependency를 해결해 준다고 말합니다.
Abstract
1. Introduction
long-range dependencies 를 capture 하는 것이 신경망에서 중요합니다.
For Sequential data( in NLP ) , recurrent 를 통해서 long-range dependency 를 capture 합니다.
For image data ( in CV) , convolution layer 를 stack 하는 방식으로 long-range dependency 를 capture 합니다.
- 이해를 돕기위해 예시를 하나 가져와봤습니다.

CNN 에서 처음에는 위 사진과 같이 이미지의 정말 low-level 수준의 feature 를 인식한다면 , 이후 layer 에서는 더 넓은 level 의 feature 를 확인 할 수 있습니다.
이미지로 자동차가 들어온 뒤 초반부 layer 에서는 low-level feature 로써 이미지의 아주 작은 부분을 확인했다면, 후반부 layer 에서는 high-level feature 인 자동차의 바퀴처럼 더 넓은 범위를 확인하는걸 알 수 있게 됩니다.
Convolutional & RNN ( recurrent neural network) 은 local neighorhood 에 대해서 연산을 수행하게 됩니다.
따라서 long-range dependecies 를 위해서 위쪽과 같이 반복적인 연산을 통해서 capture 하게 되는데 이런 방법에는 몇가지 문제점이 존재합니다.
- computationally inefficient
- optimization difficulties
- Multihop depencdency modeling
본 논문은 이러한 문제를 해결하고자 long-dependency 를 capture 할 수 있는 효율적인 방법인 non-local operation 을 제안합니다.

non-local operation 은 input feature map 에 있는 모든 포지션의 weighted sum 을 계산합니다.
Figure 1 그림을 보시면 Xi 시점에서부터 이후의 시점에 모든 포지션에 weighted sum 을 구한 뒤 relation score 가 높은 부분들을 나타낸 모습입니다.
이렇게 non-local operation 을 사용하면 몇가지 이점이 있습니다.
- Directly computing interactions between any two positions ( regradless position )
- Achieve best result even with only a few layers.
- Maintain variable input size and easily combine with other operations
비디오에서 long-range interaction 을 pixel 뿐만 아니라 time 축 역시 고려해주어야 합니다.
이때 non-local nueral networks 를 사용하면 비디오 classification 에서 기존의 2d and 3d convolution networks[48],[7] 보다 더 좋은 성능을 보입니다.
(이전 모델의 더 자세한 설명은)
[48] : 3d convolution —> https://ksh0416.tistory.com/m/79
[7]. : quo vadis,a ction recognition. —> https://ksh0416.tistory.com/m/80
또, 이전 논문과의 차이점은 RGB 만 사용한다는 점입니다. 이전 논문들에서는 two-stream 을 사용하면서 optical flow 를 사용했었는데,
non-local neural network 에서는사용하지 않고 이미지의 RGB 만 사용합니다.
Related work
Non-local image processing
Graphical models
Feed forward modeling for sequences
Self-attention
Interaction networks
Video classification architectures
3. Non-local Neural Networks
3.1 Formulation

- i : index of output position
- j : all possible position 을 enumerates 한 index
- x , y : input(video,img..) / output ( same size as x )
- f (pair-wise function) : i와 j 사이의 scalar 값 계산
- g (unary function ) : position j 에서 input signal 의 representation 계산 (cf. embedding 해준다는 의미 )
- C(x) : normlized
위 식에서 볼 수 있듯이 non-local operation 에서는 모든 포지션 ( all j ) 과 현재 index 와의 차이를 계산하게 됩니다.
CNN 은 local neighborhood 의 weighted sum 을 구하는 형태로 계산하고 ( i-1 < j < i+1 )
RNN 에서는 현재 혹은 최근의 시간 스탭을 가지고만 계산하게 됩니다. (j = i or i-1 )
또한 non-local operation 에서는 fully-connected layer ( fc layer) 와 다르게 구성되어 있습니다.
위의 식(1)을 보시면 다른 위치 사이의 relationship 을 기반으로 response 를 계산하는 반면, fc 는 학습된 weight 를 사용합니다.
게다가 non-local 에서는 고정된 input/output size 가 아닌 vairable 한 size 를 input/output 으로 가질 수 있고 positional correspondence 를 잃지 않지만
fc layer 에서는 고정된 size 와 positional correspondence 를 잃어버립니다.
(cf. vision transformer 에서도 이미지를 입력 값으로 넣고 모델에 학습시킬 때 위치정보를 보존하기 위해서 input 에 추가적인 feature 를 붙이는 걸 생각하면 될 것 같습니다 . )
3.2 Instantiations
본 논문에서는 다양한 f and g function 버전을 소개합니다.
다만, 어떤 함수를 쓰던 큰 결과의 차이는 없었고 non-local 을 사용하는 것 자체가 좋은 성능에 큰 요인 입니다.

함수 g는 linear embedding 형태를 사용합니다.
W_g 는 학습된 matrix 이고, space 에서는 1x1 conv / spacetime 에서는 3d conv 처럼 1x1x1 conv 를 사용합니다.
Gaussian.

dot-product similarity 를 사용하였다. euclidean distance 를 사용해도 되지만, dot product 가 더 deep learning에서 많이 쓰이기 때문에 선택했다고 한다.
Embedded Gaussian.
위의 Gaussian 방법에서 약간의 수정을 한 버전이다.

x 를 embedding 한 뒤 gaussain 방법과 동일하게 dot-product 를 통해서 similarity 를 구한다.
추가적으로 c(x) 는 pair-wise fucntion f 의 sum 으로 normalized 해준다.
본 논문을 읽다가 흥미로운 부분이여서 따로 정리를 해봤다.
Self-attention ( transformer) 가 non-local operations 중 embedded gaussian version 이 special case 라고 본 논문에서 주장한다.

당시에 Transformer 구현해보고 있어서 논문 읽고나서 잠깐 정리해 둔 것인데. 사실 transformer 가 non-local 의 special 한 버전이라는 점에 의의를 두기 보다는
당시에는 transformer 가 nlp 정도에서만 쓰였던 것으로 알고 있는데 non-local nerual network 논문이 나오면서
수식이 유사한 non-local 이 vision 에서 잘 쓰이고 있으니, transformer 도 computer vision 에서의 가능성을 열었다. 정도로만 이해하면 될 것 같았다.
Dot product .

Concatenation.

Dot product 는 softmax 를 사용하지 않은 형태이고,
concatenation 은 concat 한 이후에 Relu 에 넣는 형태로 연산을 진행한다.
3.3 Non-local block
Non-local block 을 다른 architecture 에서도 사용하기 위해 기존 y 값에 wrap 를 해준다.
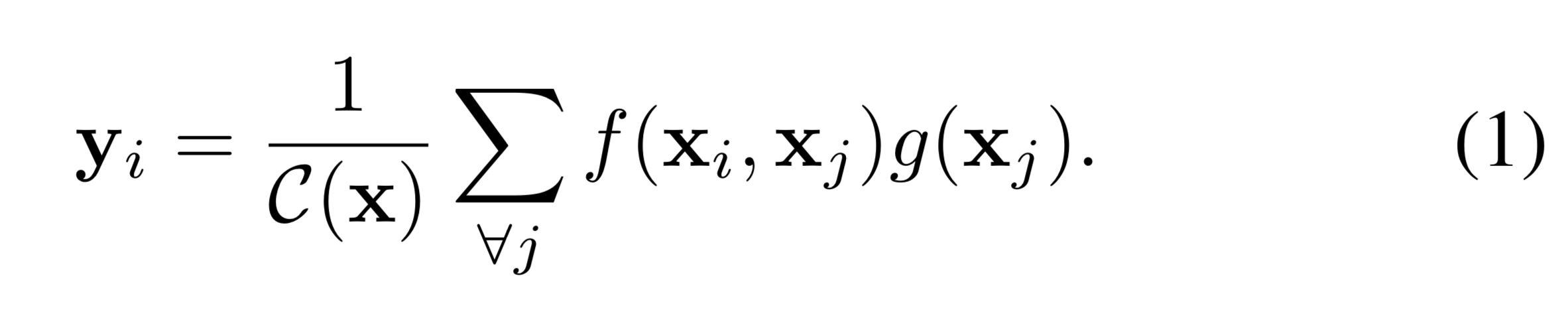
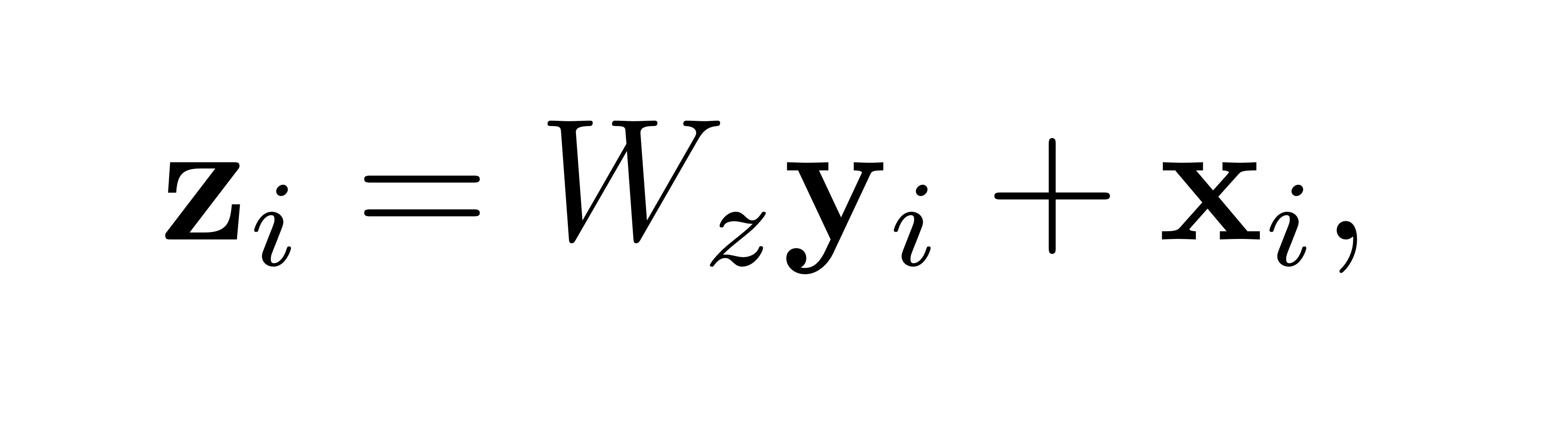
+ X_i 는 residual connection 인데, 이게 있어서 non-locak block 을 이미 학습된 모델이라도 넣을 수 있게 된다.
( W_z 의 초기값을 0 으로 설정하면 input/output 모두 x_i 가 되기 때문에 학습에 영향을 미치지 않는다 )
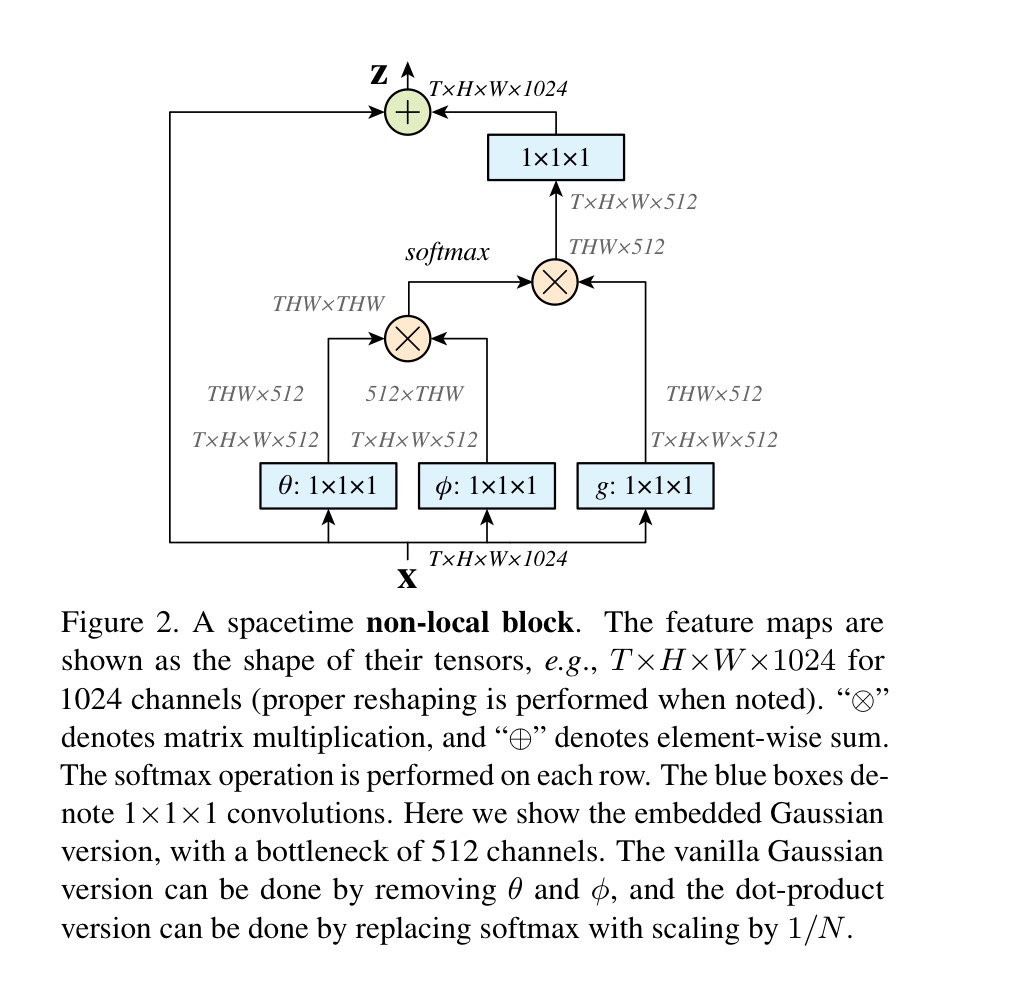
embedded gaussain 일 때 non-local block 의 형태입니다. 위에 나온 수식들을 그대로 도식화한것이라 다른 설명없이 넘어가겠습니다.
4. Video Classification Models
Non-local 네트워크의 동작을 이해하기 위해서, video classification task 에서 ablation experiments 를 한다. baseline network 구조를 설명하고, 이를 3D ConvNets 으로 확장하고 Non-local net으로 제안합니다.

2D ConvNet baseline (C2D)
3D ConvNet 과 다르게 temporal dimension 을 고립(분리) 시키기 위해, 2d baseline architecture 를 설계합니다. Table 1 은 ResNet-50 을 backbone 으로 사용한C2D baseline 입니다. table 1 의 모든 convolution 은 input 을 frame-by-frame 으로 처리하는 2d kernel 입니다. (1xkxk kernel ) 또한 이 모델은 imageNet으로 pre-train 되었습니다.
이 모델에서 temporal information 을 포함시키는 유일한 방법은 pooling layer 입니다.
( 2d baseline 은 간단하게 시간 정보와 통합된다는 의미 )
Inflated 3D ConvNet (I3D)
이번에 사용한 모델은 Inflated 3D ConvNet(I3D) 모델입니다. 표1 의 C2D 모델을 “inflating” 해서 만들 수 있다. 예를 들어서
위에서 살펴본 2D kernel ( 1xkxk ) 를 3D ( t x k x k) 로 inflated 한다. 또한 이 모델은ImageNet 에서 pre-trained 된 2D model 로 부터 initialized 되어 사용됩니다.
I3D 에 대한 더 자세한 내용은 https://ksh0416.tistory.com/m/80 를 참고하시길 바랍니다.
Non-local network
본 논문에서는 Non-local block 들을 baselien C2D or I3D 에 넣어서 non-local net 으로 변형시키고 결과를 측정합니다.
5. Experiments on Video Classification
Kinetics data set 을 사용하여 실험합니다.
5.1 Experiments on Kinetics

위의 그래프는 ResNet-50 C2D baseline vs non-local C2D 비교 모습을 보여준다. non-local 을 사용한 모델이 일관성있게 C2D baseline 보다 결과가 좋은 것을 확인 할 수 있다.

Figure 3 는 non-local block 을 시각화한 그림이다. Non-local block 을 이용한 network 는 space and time 과 상관없이 menaingful relation 을 학습할 수 있다.
좀 더 편하게 보기 위해서 기준이 되는 frame 위에 빨간색 체크 표시를 해두었다. 체크표시를 한 frame 들과 다른 frame 들간의 relation 을 시간의 전/후, 공간과 관계없이 잘 찾는 걸 확인 할 수 있다.
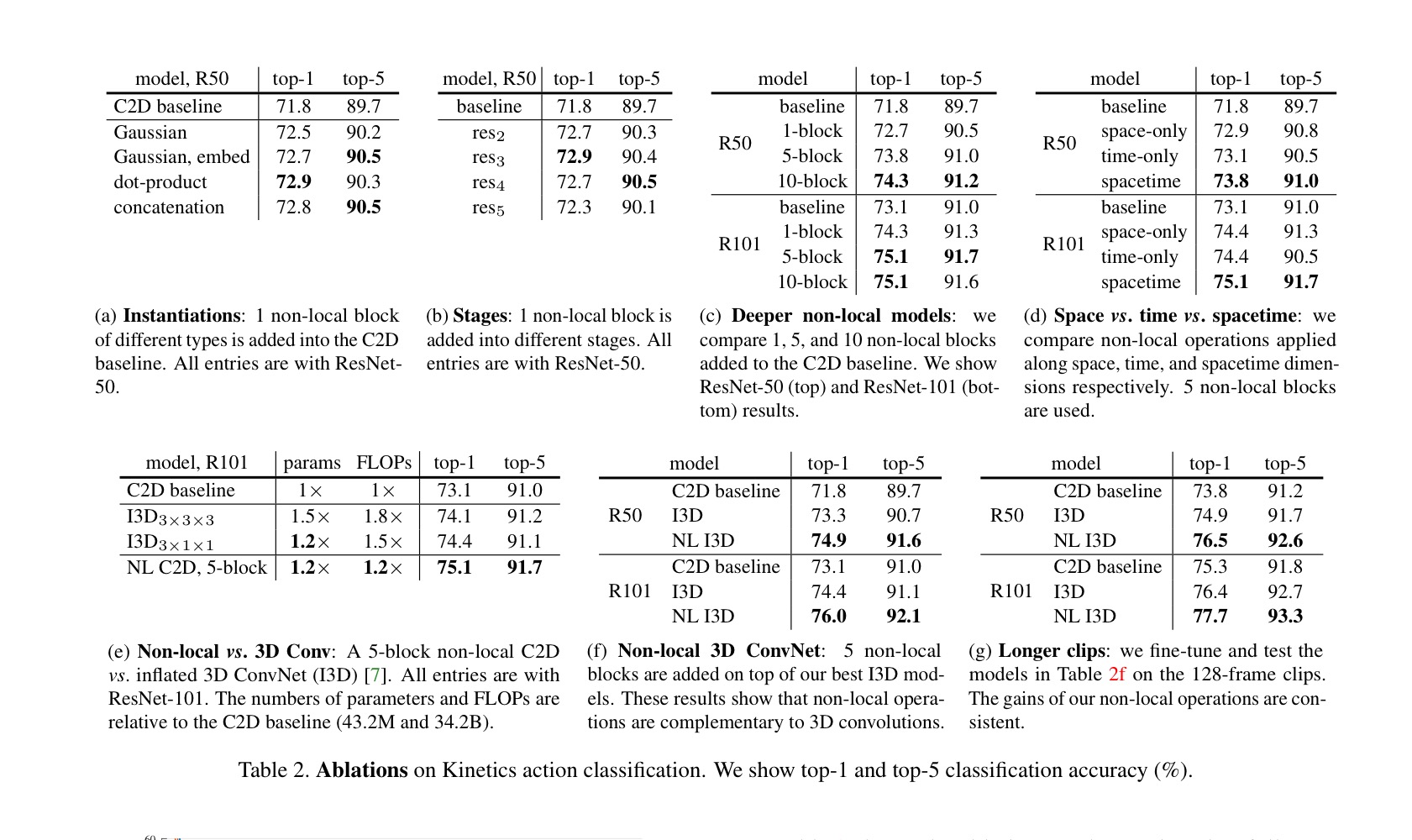
instantiations.
(a) 는 C2D baseline 에 추가된 non-local block 에 대한 비교이다. 한개의 non-local block 만 추가 되어도 1% 이상의 정확도를 향상 할 수 있다.
여기서 흥미로운 결과는 gaussian embedded , dot porduct , concatenation versions 는 수행 결과가 비슷하다는 점이다( 72.7 to 72.9). 이는 위에서 언급했듯이 어떤 함수를 사용하느냐가 key 가 아니라 non-local behavior 을 사용하는 것 자체가 중요하다고 볼 수 있다.
Going deeper with non-local blocks.
Table 2 (C) 는 non-local block 개수에 따른 결과 표 이다. 대체로 non-lock block 이 많이 추가 될 수록 성능이 좋아지는 모습을 확인 할 수 있다. 이는 non-local block 이 long-range multi-hop communication 하고 있는 것을 알 수 있다.
또 주목해야 할 점은 non-local block 이 base modle 의 깊이를 추가한 점이 아니라는 것이다. (c) 를 보면 5 non-local block Resnet-50 의 정확도가 73.8 인데 Resnet-101 의 baseline의 정확도가 73.1% 이다. 파라메터와 Flow 역시 resnet-50 이 더 적고 얕다. 이러한 점을 보았을 때 non-local blocks 이 standard 방법으로 더 깊이 들어가는 것을 보안하기 때문에 성능이 향상된다고 볼 수 있다.
( 위의 말이 이해하기 조금 난해해서 조금 더 쉽게 풀어서 이해해 보자.
기존의 방식에서는 network 를 더 깊게 하는 것으로 성능을 증가시키면서 이점을 얻는 방식이었다(standard).
non-local 방식은 그런 standard 의 깊이를 증가시키는 것 만으로 얻는 이점과 별개로 성능을 향상 시킬 수 있다는 말로 이해하면 될 것 같습니다. )
conclusion
- Long-range dependency를 caputre 가능한 새로운 neural network 제시.
- non-local block 은 다른 architecture 에도 결합 가능. ( + 여러 task 에도 사용 가능)
Code review
https://github.com/AlexHex7/Non-local_pytorch/blob/master/Non-Local_pytorch_0.3.1/lib/non_local_embedded_gaussian.py
논문에서 처럼 4가지 함수로 구현되어 있는데, embedded gaussian 만 살펴보겠습니다.
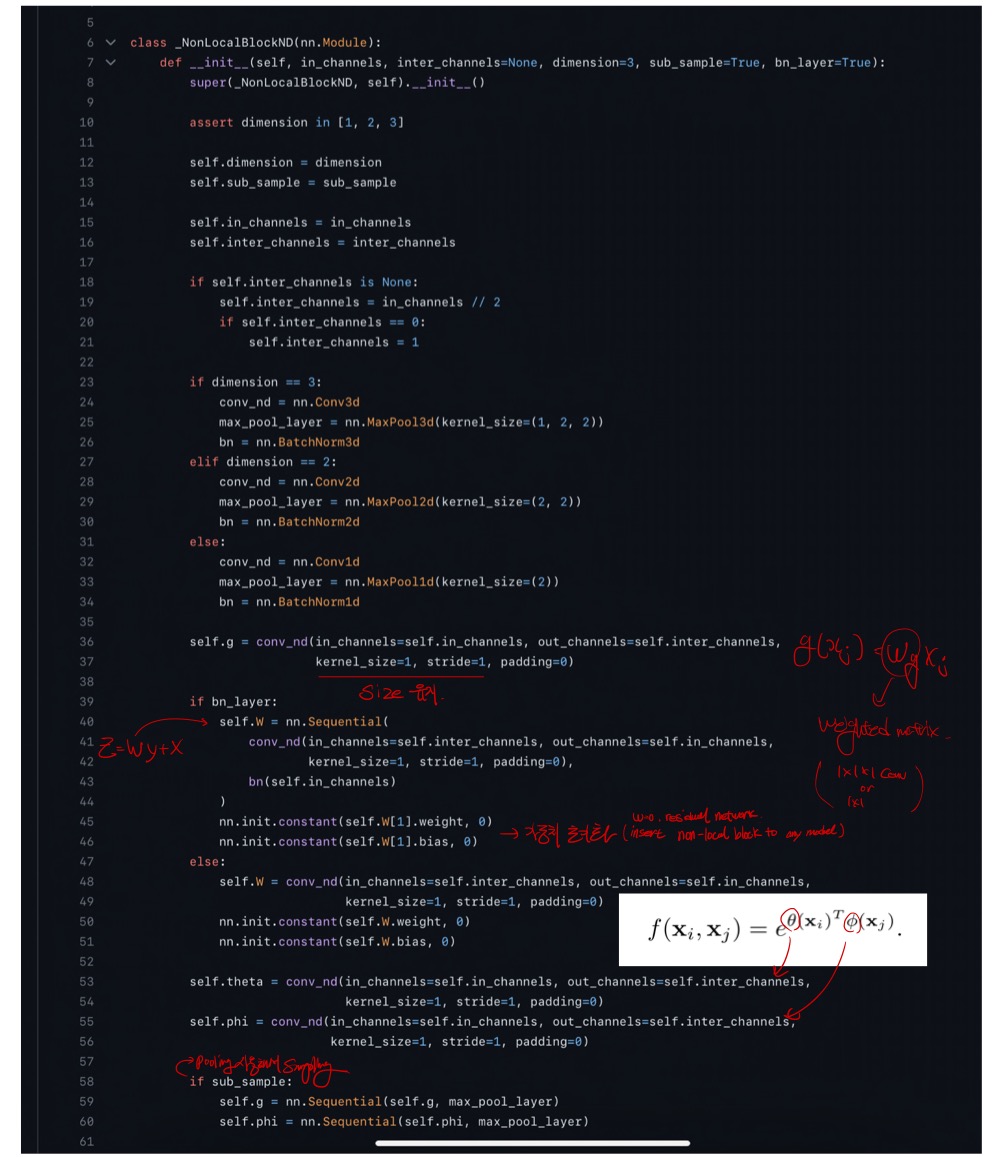

이해를 대부분 했는데, 글로 설명하기가 좀 어려워가지고 일단은 공부할 때 했던 필기로 대체해서 올린다.
이것 말고도 resnet-50 에 non-local 넣은 코드나, train/eval 한 코드들을 이해하고 확인하긴 했는데 다른 코드들과 큰 차이점은 없어서 일단은 생략했다.
느낀점
- 이미 있는 기존의 모델에 새로운 방식을 끼워넣는게 신기했다. 내 상식 안에서는 non-local block 이 갑자기 기존 resnet 안에 들어가서 연산한다면 기존에 했던 연산들의 일관성이 깨지면서 성능이 오히려 저하 될 것 같았는데 효과가 좋아서 조금 놀랐다. 같은 맥락으로 처음 논문의 abstract 를 봤을 때는 당연히 non-local block 으로만 이루어진 새로운 모델일 줄 알았는데, 그것도 아니여서 놀라웠다.
- 다른 모든 frame 들과 non local mean 을 계산하면 parameter 수가 기존 conv 계산보다 훨씬 많을 것 같은데, 연구결과에 의하면 큰 차이가 없다.(오히려 적었던 것 같은데)
그래서 코드보면서 확인을 좀 하려고했는데 fucntion f(X_i,X_j) 이부분 구현에서 살짝 이해가 안되는 부분이 j 는 다른 시간의 frame 의 전체 이미지이고 이 j와 x_i 사이의 계산인데 반복문을 안쓰고 바로 저런식으로 구현을 할 수가있나? 싶었다.
—>
- implementation detail 이나 experiments 같은 부분이 원래 논문 읽을 때 읽기 난해하거나 거부감이 들었는데, 읽고나서 코드보고 다시한번 더 보니 괜찮았던 것 같다.
- 파이토치에 대한 이해도가 떨어지기도 하고 실제로 코딩을 사정상 못하다보니 ” 파이토치 딥러닝 마스터 “ 라는 책을 읽고 있는데 읽으면서 나왔던 코드 패턴이나, 함수들이 나오다보니 이전보다 코드 리뷰하거나 코드 보는게 훨씬 편해진게 체감이 된다.
( 책을 읽기만해도 이정도인데, 실제로 구현하면서 배우면 정말 얻을게 많을 것 같다.)